Igazságkereső AI helyett MuskGPT lett a milliárdos chatbotjából, a Grokból

„A maximális igazságkeresés a legjobb megfejtésem a biztonságos mesterséges intelligenciára”
– írta Elon Musk az X-en 2023 márciusában.
Innen jutottunk el két év alatt oda, hogy a milliárdos xAI nevű vállalata által kifejlesztett Grok chatbot július elején Musk közösségimédia-posztjaira alapozva döntötte el, mit válaszoljon az izraeli-palesztin konfliktusról, az abortuszszabályozásról, valamint az amerikai bevándorláspolitikáról feltett kérdésekre.
Nem ez az egyetlen dolog, ami mostanában megtépázta az xAI chatbotjának megítélését, amit a vállalat az egész emberiségnek készülő mesterséges intelligenciaként hirdet. A Grok július elején több, azóta törölt posztban „MechaHitler”-nek nevezte magát az X közösségi platformon adott válaszaiban, valamint rasszista és antiszemita kijelentéseket tett.
Erre napokkal azután került sor, hogy Musk, aki emlékezetes módon januárban náci karlendítésre emlékeztető mozdulatával keltett botrányt, azt közölte, hogy „jelentősen javítottak” a chatbot képességein. Az internet erre a „javításra” tényleg felfigyelt, írta a Politico, aminek hála az elmúlt hetek hírei a Grok megbotránkoztató válaszairól, és nem a chatbotot működtető új AI-modell, a Grok 3-at váltó Grok 4 képességeiről szóltak. Pedig erre is érdemes figyelni, mivel a modellek fejlettsége potenciálisan növelheti az általuk okozott károkat – és az xAI a július 9-én kiadott Grok 4-gyel egy sor teszteredmény szerint felzárkózott az OpenAI-hoz (ChatGPT) és a Google-höz (Gemini).
„Rettentően sok minden mehet félre, ha nem kezeljük ezeket a modelleket felelősséggel” – nyilatkozta a Qubitnek Gyevnár Bálint, az Edinburgh-i Egyetem doktorandusza, aki az AI-biztonság terén folytat kutatásokat, és azért dolgozik, hogy az AI-ágensekként ismert, autonómabb mesterséges intelligencia rendszerek viselkedése beláthatóbb legyen. A szakember egyes területeken jelentős eltéréseket lát más chatbotok és a Grok között – utóbbi például a felhasználóknak könnyebben ad veszélyes információkat, például vegyi és biológiai fegyverekről.
A magyar kutató nemrég közös tanulmányt közölt Atoosa Kasirzadeh mesterséges intelligenciával foglalkozó filozófussal az AI-biztonságról, ami a rangos Nature Machine Intelligence folyóiratban jelent meg. Kasirzadeh tavaly adott interjút a Qubitnek, ahol az európai mesterségesintelligencia-szabályozásról (AI Act), és az AI-rendszerek által jelentett mai és jövőbeli kockázatokról kérdeztük.
A Grok 4-gyel felzárkóztak a többi nagy amerikai AI-céghez
Musk az xAI-t szinte pontosan két éve, 2023 júliusában alapította meg azzal a céllal, hogy létrehozza a „TruthGPT”-t, és véget vessen a szerinte túl PC és politikailag elfogult ChatGPT uralmának. A Grok, amely az X közösségi platformon és saját alkalmazáson keresztül is használható, az idén februárban debütált Grok 3-mal lett igazán versenyképes, és a 200 000 GPU-s klaszteren tanított Grok 4 ehhez képest is komoly előrelépést jelent.
Az xAI által másfél hete bejelentett Grok 4 és a még jobb teljesítményű Grok 4 Heavy a ChatGPT o3-jához, és a Gemini-2.5-Pro-hoz hasonlóan „érvelő” (reasoning) modellek, amelyek válaszaikon a hagyományos nagy nyelvi modellekhez képest többet gondolkodnak. A Grok 4 képes eszközöket is használni, például keresni az interneten, vagy Python programnyelv segítségével műveleteket végezni.
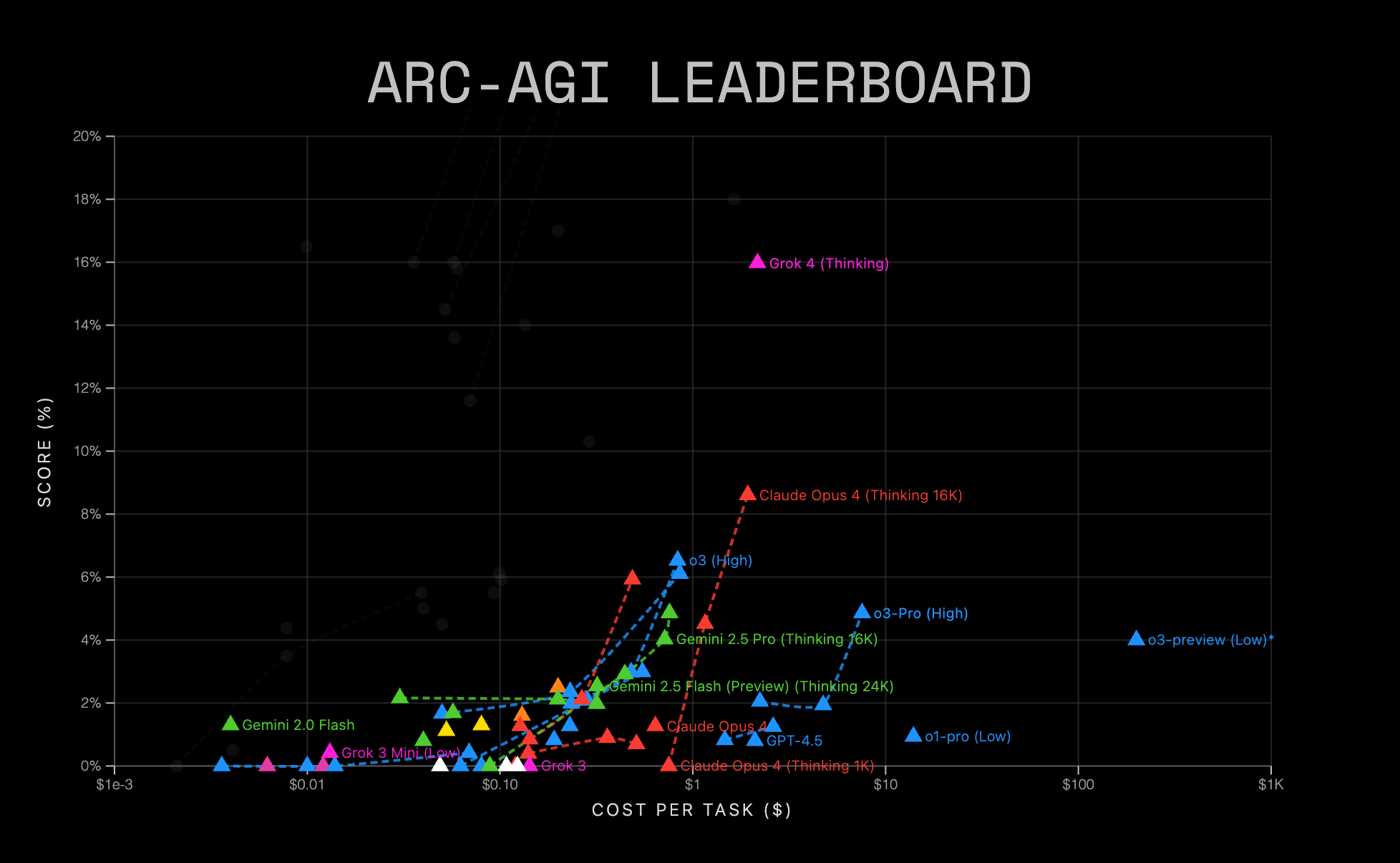
A Grok 4 az elismert ARC-AGI 2 teszten, ami puzzle-ökkel teszteli az AI-modellek általános intelligenciáját, az eddigi legjobb eredményt érte el 16 százalékkal, maga mögé utasítva az o3-at, a Gemini 2.5 Prót, valamint az Anthropic Claude Opus 4 chatbotját. Az xAI modellje hasonlóan jól teljesített a Humanity’s Last Exam (az emberiség utolsó vizsgája) nevű teszten, 25,4 százalékos pontosságával megszerezve az első helyet (a Gemini 21,6, az o3 20,3 százalékot ért el). Egy harmadik, LiveBench nevű teszten, ami az egyik legmegbízhatóbb chatbotrangsort állítja elő, a Grok 4 vezet érvelési képességet tekintve, és összességében harmadik helyen áll az o3 és a Claude 4 után.
A MechaHitler a „woke” eltávolítási kísérletének eredménye lehet
A cikk innentől csak a Qubit+ előfizetőinek elérhető.
Csatlakozz, és olvass tovább!
Ha már van előfizetésed, lépj be vele. Ha még nincs, válassz csomagjaink közül!