Bárki hangját képes utánozni a Microsoft új mesterséges intelligenciája

3 másodperc alatt bárkitől eltanulja a beszédstílusát a Microsoft által fejlesztett VALL-E intelligenciamodell, írja az Ars Technica. Ezzel komplett szövegek felolvasása válik lehetségessé anélkül, hogy valódi embereket kellene alkalmazni. A technológia pedig lehetőséget ad arra is, hogy egy felvétel tartalmát akár utólag szerkesszék.
A VALL-E egy neurális nyelvmodell (neural coding language), amely a Meta által 2022 októberében bemutatott EnCodec technológiájára épül. Ez a tömörítési megoldás az elterjedten alkalmazott MP3 formátumhoz képest 10-szeres tömörítést tesz lehetővé audiofájlokon a mesterséges intelligencia használatával. A Meta szerint erre a Metaverzum információinak tárolása miatt van szükség, de a VALL-E fejlesztése is azt mutatja, hogy más területeken is alkalmazható.
Az intelligens beszédszintetizátor a hangminta alapján felismert sajátosságokat képes alkalmazni más szövegrészletek felolvasásakor. Más módszerekkel ellentétben nem hullámformák manipulációját aknázza ki, hanem helyette diszkrét audiokódokat generál a szöveg és az akusztikus jellemzők alapján.
Részleteiben elemzi a beszédmintát, a jellemzőket pedig az EnCodec segítségével összetevőnként (tokenenként) rögzíti, majd ezeket alkalmazza a felolvasáskor. Erre több példa is elérhető a VALL-E weboldalán, ahol a Meta által összeállított LibriLight hangkönyvtáron kiképzett intelligencia egy sor minta felolvasásával demonstrálja tudását.
A fejlesztők is elismerik, hogy ahhoz, hogy a hangmintához tényleg megtévesztésig hasonlító eredmény szülessen, fontos, hogy a betanító hangkönyvtár tartalmához némiképp hasonló beszédet mutassanak a modellnek. Ugyanakkor az intelligencia nemcsak a beszélő jellemző hangszínét és beszédstílusát képes megőrizni, hanem az akusztikai környezetet is, így szimulálható vele például telefonhívás is.
Talán pont a sokoldalúsága lehet az oka annak, hogy a Microsoft a forráskódokat és magát a rendszert sem tette egyelőre elérhetővé. A beszédszintetizátor ugyanis olyan eredményes az utánzásban, hogy felvételek manipulációjára, és jó minőségű deepfake tartalmak előállítására is alkalmas lehet. Ezért egyelőre nincs mód a saját hangunkon is kipróbálni a rendszert.
Kapcsolódó cikkek a Qubiten:

Egy robotot eresztenek rá Károly király első karácsonyi beszédére a brit Channel 4-on
A tévécsatornánál már hagyománynak számít, hogy alternatívát állítanak a BBC hivatalos karácsonyi üzenetének – két éve deepfake II. Erzsébet királynővel borzolták a kedélyeket, most a mesterséges intelligenciához fordultak.
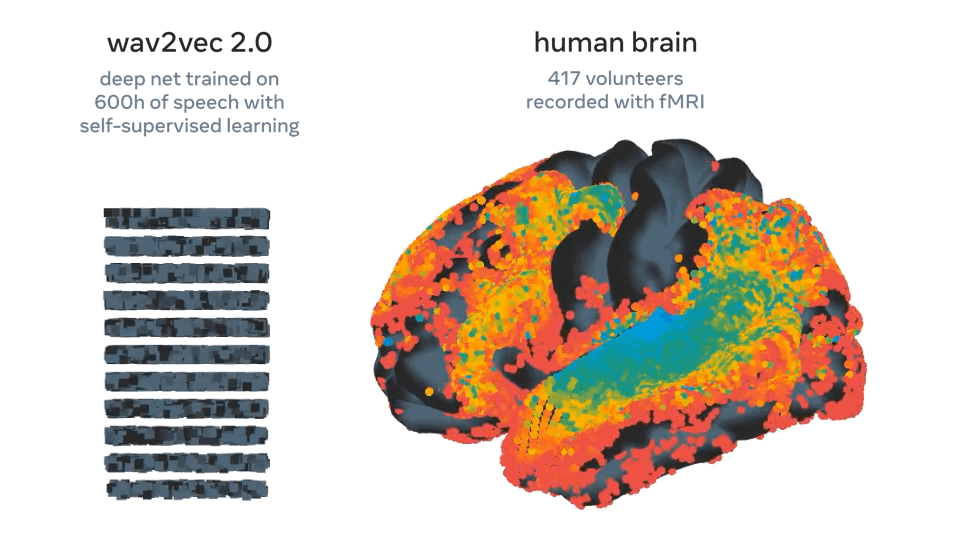
A Meta olyan mesterséges intelligenciát fejlesztett, amely az agyhullámokból találja ki, mit mondunk
A rendszer 73 százalékos pontossággal megjósolta, hogy egy elhangzott beszéd milyen szavakat tartalmazott, és bár korai szakaszában jár a technológia, a legtöbb hasonló megoldással szemben nincs hozzá szükség invazív beavatkozásra.
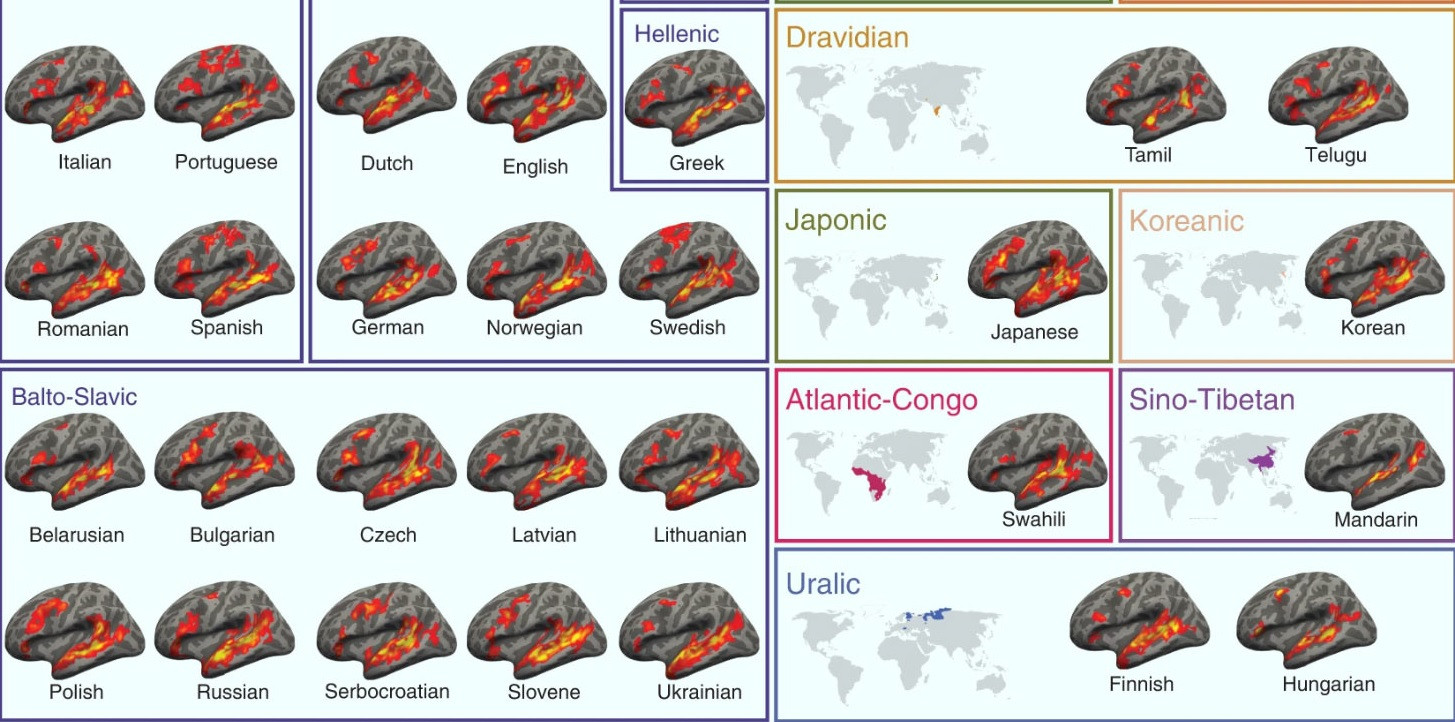
Univerzálisnak tűnik a nyelvfeldolgozás agyi hálózata
A Massachussets Institute of Technology kutatói fMRI-felvételek alapján azt állítják, hogy ugyanazok az agyterületek aktiválódnak függetlenül attól, hogy mi az illető anyanyelve.
