Alfaszor vagy alfászor – mindegy? Paradigmaváltás a nyelvészetben

Az 1980-as évek fordulata
Nem szeretem a túlzottan általánosító nagy történelmi állításokat, de most mégis egy ilyennel kell kezdenem. Amióta az emberek kifinomult mechanikus gépeket (például órákat) fabrikálnak, az agy működését gyakran az ilyen gépekéhez hasonlították. Ez volt az uralkodó elképzelés a 18. és a 19. században. A 20. század elejétől persze megjelent a számítógép-hasonlat, és ezzel együtt – mivel a számítógép logikai lépéseket hajt végre, és mivel akkoriban lendült fel a matematikai logika tudománya – az elme működését egyre inkább matematikai vagy logikai levezetések végrehajtásaként képzelték el. Ez uralkodott az ember nyelvi tevékenységeinek felfogásában is. Vagyis úgy gondolták, hogy a fejünkben axiómarendszerek és levezetési szabályok vannak: a kimondott megnyilatkozások is, a megértés eredménye is úgy jönnek létre, hogy az agyunkban levezetéseket hajtunk végre.
Ennek a 20. századi felfogásnak a nyelvészetben a legelterjedtebb és egy ideig egyeduralkodó megvalósítása Noam Chomsky ún. generatív grammatikája volt (ez 1957-től vált általánosan ismertté). Ebben a generatív szó éppen arra utal, hogy egy zárt és statikus adatbázisból (ami az axiómarendszert, a szókincset és a levezetési szabályokat tartalmazza) vezetjük le, generáljuk a nyelv mondatait és az értelmezésüket. A matematikához és a logikához hasonlóan a generatív nyelvtanban is feltételezik, hogy az axiómák a lehető legszűkebbek és -takarékosabbak (nincs bennük redundancia, vagyis semmi sem szerepel bennük többszörösen), és a levezetési szabályok maximálisan általánosak és teljesen szabadon működtethetők, bármikor bármelyik alkalmazható, pont úgy, ahogy a matematikában és a logikában is.
A generativista elképzeléssel szembeni legkomolyabb empirikus kihívások Joan Bybee amerikai nyelvész felfedezéseihez kötődnek (az 1980-as évektől). Ő azt ismerte fel, hogy a nyelvhasználat bizonyos jellegzetességeit igen nehéz lenne a generatív szemlélet alapján megmagyarázni, különösen pedig a szabályrendszer maximális általánossága és a redundancia hiánya vezet problémákhoz. Például ő ismerte fel, hogy a nyelvi kifejezésekre vonatkozó szabályszerűségek érvényesülése nagyban függ az illető kifejezések előfordulási gyakoriságától, és ennek a jelenségnek semmiféle megfelelője nincs a matematikai és logikai levezetések világában. Azt is kimutatta, hogy a nyelvi kifejezésekre való tudásunkat nem tárolhatjuk takarékosan, nemcsak a legfontosabb nyelvi jellemzőikre kell emlékeznünk, hanem nagyon sok esetleges, alkalmi jellegzetességükre is, mert ha nem így lenne, akkor egy sor jelenséget nem tudnánk megmagyarázni.
Ami a gyakoriság hatását illeti, az egyik legszebb példa az angol nyelvnek az a szabályszerűsége, hogy egyes esetekben a hangsúlyos szótagot követő [ə] hangot nem szokták kiejteni. (Ez egy sem nem felső, sem nem alsó, sem nem elöl, sem nem hátul képzett magánhangzó, az ún. schwa, mint amilyet az angol a(n) névelő kiejtésében hallunk.) Így a memory `emlék, emlékezet' szót inkább [memri]-nek ejtik, csak ritkábban [meməri]-nek. Viszont ez a szabályszerűség annak arányában érvényesül, hogy milyen gyakori az illető szó. Például a mammary `emlővel kapcsolatos, emlő-' szót sokkal ritkábban ejtik [mæmri]-nek (schwa nélkül), mint a memory-t: inkább [mæməri]-nek ejtik (kimondott schwa-val). Ugyanakkor a schwa nélküli, ritkább kiejtés sokkal gyakoribb azoknak a beszédében, akik ezt a szót az átlagnál gyakrabban használják (biológusok, orvosok stb.).
A nem takarékos tárolásnak vannak kísérleti bizonyítékai is (például olyanok, amik szerint olyan toldalékolt alakokat is tárolunk az agyunkban, amik nem kivételesek, tehát a szabályrendszerünk alapján is könnyedén levezethetnénk), de szükséges feltételezni a nyelvi változásmagyarázatához is. (Olyan kiejtési változatokra is emlékszünk, amik jelenleg még nem térnek el jelentősen a leggyakoribbaktól, de nem terjednének tovább, és idővel nem vennék át a korábbi változatok helyét, ha a beszélők memóriájában nem lennének eltárolva, és nem produkálnák őket egyre inkább maguk is.)
Csak röviden említem meg, hogy mi volt mindezekre a felismerésekre a generatív nyelvészet válasza. Ők eleve megkülönböztették a nyelvre vonatkozó statikus, adatbázisszerű ismereteket (az ún. kompetenciát) azoktól a képességektől, amelyek ezeknek az ismereteknek a használatát biztosítják (ez az ún. performancia). Utóbbiakat egyáltalán nem is tekintették nyelvi természetűnek, és nem sokat foglalkoztak velük. (Ide tartozik például a rövid- és hosszútávú memória használata, a beszédszervek mozgásának vezérlése, a kommunikációban fontos akusztikus tényezők stb.) Mindazokat a jelenségeket és problémákat, amikre Bybee és mások felhívták a figyelmet, ők a nyelvi kompetenciától függetleneknek, a performancia körébe tartozónak nyilvánítják, és nem látják be, hogy ezek a felfedezések aláássák magának a kompetencia – performancia megkülönböztetésnek a létjogosultságát is, hiszen arra utalnak, hogy a kompetenciának mint maximálisan általános és takarékosan tárolt tudásbázisnak a létezésére egyre kevesebb tapasztalati bizonyítékunk van.
Emergens és konstrukciós nyelvtan
Az 1980-as évek végére a Bybee-féle felismerések egy olyan nagy paradigmaváltást indítottak el a nyelvészetben, aminek még most is csak a közepén vagyunk, új „standard” elméletről még nem beszélhetünk, de rengeteg hasonló irányban haladó kezdeményezésről igen. Ebből a szempontból az 1987-es évet szimbolikusan határkőnek tekinthetjük, mert két dolog történt ekkor. Egyrészt Charles Fillmore és Paul Kay abban az évben adták elő először a konstrukciós nyelvtan nevű elméletüket az LSA nyári egyetemén (ezen véletlenül én is ott lehettem). Másrészt megjelent Paul Hopper Emergent Grammar (Emergens nyelvtan) című cikke, amire még ma is sokan hivatkoznak, bár rövid és sok szempontból kidolgozatlan.
Valamilyen értelemben a konstrukciós és az emergens irányzat is azt a vonalat építi tovább, amiről a Bybee-féle felismerésekkel kapcsolatban beszéltem (bár egyikük sem hivatkozott Bybee írásaira). És érdekes módon az új paradigma melletti érvek szempontjából bizonyos értelemben mindegy is, hogy mit képzelünk a beszélők fejébe, mindenképpen arra mutatnak, hogy a generativista megközelítés problematikus.
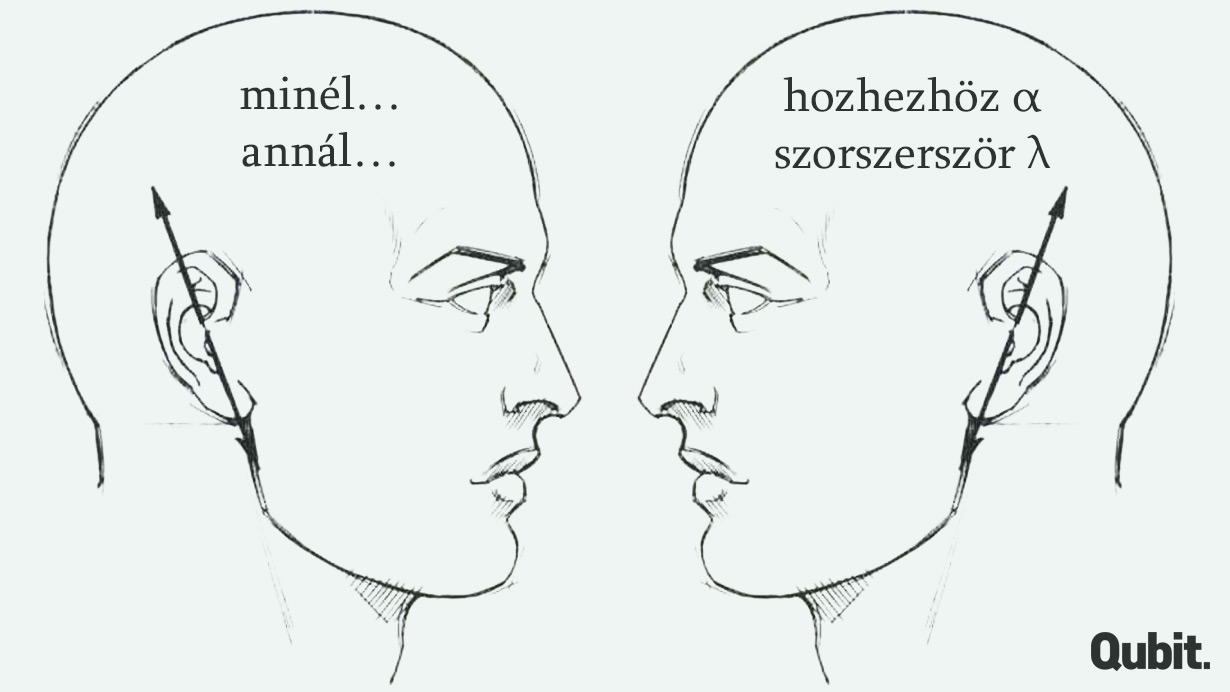
A konstrukciós irányzat elsősorban az ellen érvel, hogy a nyelvi képességünk úgy működik, mintha a fejünkben valamiféle minimális axiómarendszer és maximálisan általános levezetési szabályok lennének. A fő érvei azon alapulnak, hogy milyen jellegű is az a tudásunk, ami a nyelvi képességeink alapjául szolgál. Szerintük rengeteg olyan „félkész” szerkezet ismeretét kell feltételeznünk, amelyeket nem tudunk maximálisan általános szabályok segítségével levezetni, hanem memorizálnunk kell. Ezek különböző szempontokból megfelelnek ugyan mindenféle nyelvi szabályszerűségnek, de mégis vannak sajátos vonásaik, amelyek miatt külön tárolnunk kell őket. Ilyen szerkezet például a minél ..., annál ... mondatminta (ennek angol megfelelője volt az egyik első kidolgozott példa a konstrukciós szakirodalomban). Az ilyen mondat rengeteg magyar szabályszerűségnek megfelel, a minél és az annál is létező magyar szavak, de a jelentésükből aligha lehet levezetni, hogy éppen így kell kifejezni azt a jelentést, amit az ilyen mondat hordoz, és az így alkotott mondatok egyéb tulajdonságai sem következnek általános szabályokból. (A részletektől itt eltekintek.)
Az emergens nyelvtan koncepciója inkább azt hangsúlyozza, hogy hogyan érvényesülnek a nyelvi szabályszerűségek. Itt a fő érv az, hogy nem egy kész szabályrendszerrel indulunk neki a kifejezések létrehozásának és megértésének, amit aztán vakon alkalmazunk, hanem csak különböző korábbi tapasztalatainkat aktivizáljuk, és némileg rugalmasan alkalmazzuk őket. Vagyis nincs kész „nyelvtudásunk” egy előre adott, statikus nyelvről, hanem lényegében majdnem minden megnyilvánulásunkkal egyszerre alkalmazkodunk nyelvi szokásokhoz, és közben formáljuk is azokat. Így például, amikor kimondjuk a fent említett memory vagy mammary szavakat, akkor nem egy „schwa-törlő szabályt” alkalmazunk (vagy nem alkalmazunk), hanem csak felidézzük, hogy a hozzájuk hasonló szavakat milyen gyakran milyen kiejtéssel hallottuk. Ezt az is jól mutatja, hogy ha egy bizonyos kifejezéstípussal különlegesen ritkán (esetleg sosem) találkoztunk korábban, akkor bizonytalankodunk – ezt egy generatív szabályrendszer feltételezésével aligha tudnánk megmagyarázni. Például a magyar -szor/-szer/-ször végződés csak számokhoz járul, a számok között pedig nincs -a/-e végű. Ezért hiába tartozik a -szor/-szer/-ször a toldalékok teljesen általános típusába (ugyanabba, mint mondjuk a -hoz/-hez/-höz), elbizonytalanodunk, ha ezzel a toldalékkal kell ellátnunk a lambda, alfa szavakat (amik mindenféle tudományágak szokásai szerint jelölhetnek számokat): nem tudjuk, hogy a lambdaszor, alfaszor, vagy inkább a lambdászor, alfászor „van-e inkább magyarul”.
Paradigmaváltás és „big data”
Visszatérve azokhoz a nagyívű történelemvíziókhoz, amiktől annyira idegenkedem, a mostani nyelvészeti paradigmaváltásra is ráilleszthető ilyen vízió. Annak ellenére, hogy az 1980-as években még nem hallottuk minden nap a big data kifejezést, feltűnő, hogy a nyelv felfogásában történő változás mennyire párhuzamos például a gondolkodás felfogásában történővel. A legtöbb mai alakfelismerő, problémamegoldó stb. rendszer (és ezeknek az elméleti alapja, az ún. mesterséges intelligencia) a 20. századiakkal szemben nem statikus és minimális axiómarendszeren, valamint szabadon működő, általános levezetési szabályokon alapul, hanem hatalmas, nagyon gazdag és redundáns adatbázisokon, valamint sztochasztikus összehasonlító és rekombináló műveleteken (ld. pl. erről Robert Epstein cikkét ). A nyelvészetben ezek a hatalmas adatbázisok a memorizált nyelvi tapasztalatainknak felelnek meg, azt pedig, hogy ezeket hogyan alkalmazzuk, azt nagyjából ugyanúgy képzelték el már az 1980-as évek „reform-nyelvészei” is, mint ahogy most a mesterséges intelligencia kutatói.
A szerző nyelvész, az MTA Nyelvtudományi Intézetének főmunkatársa. A Qubit.hu-n megjelent írásai itt olvashatók.