Ugyan nem várta el senki, a Google egyik AI modellje mégis megtanult bengáliul

Roppant kevés bengáli szöveg segítségével tanította meg önmagát a nyelv használatára a Google egyik mesterséges intelligencia (MI, angolul AI) modellje, számolt be róla a vállalat technológia és társadalmi kapcsolataiért felelős alelnöke, James Manyika a CBS 60 Minutes című műsorában. A beszélgetést a Quartz szemlézte.
A meglepően gyors és kevés információn alapuló tanulás ugyanakkor elég sikeres, a modell ugyanis komplett szövegeket képes lefordítani. Az viszont, hogy mindez hogy lehetséges, nem igazán tisztázott. A mesterséges intelligencia modelleket fejlesztő szakemberek az ilyen kérdéseknél hivatkoznak fekete dobozként a modellekre.
Bár a Google-nek már van néhány ötlete, hogy lehetséges, hogy a modell önállóan tanulta meg a nyelvet, egyelőre nincs biztos magyarázat. A műsorvezető, Scott Pelley ezért rákérdezett Sundar Pichai vezérigazgatónál, hogy miért tették publikussá a Google nyelvi modelljét, ha annak még számos teljesen ismeretlen működése van.
A Google vezérigazgatója erre azzal válaszolt, hogy az emberi elme működését sem ismerjük száz százalékban. Ezután a beszélgetés a Bard hibáira terelődött, amiket a szakemberek szerint robosztusabb modellek fejlesztésével lehetne kiküszöbölni.
Kapcsolódó cikkek a Qubiten:
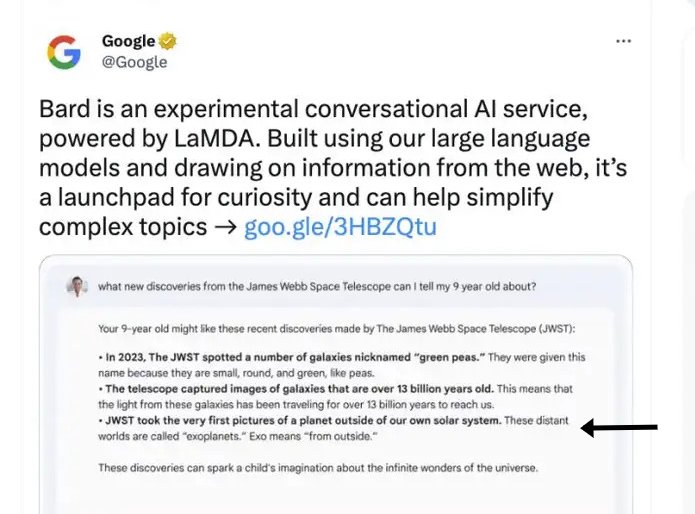
Még meg se jelent, máris tévedett a Google kereső-chatbotja, a Bard
A Microsoft, a Google és a Baidu is azt ígéri, hogy nemsokára elindul a chat-alapú keresőszolgáltatása, de a Bard már a kezdet kezdetén, a működését bemutató reklámban is bakizott. A szakértők aggódnak, hogy ilyesmi gyakran előfordulhat a hasonló kereséseknél.

„A verseny elkezdődött” – a Microsoftnál új korszak indul, ami a ChatGPT-re épül
Rendesen odaszúrt a Google-nek a Microsoft a ChatGPT-vel felturbózott Bing és Edge bemutató eseményén. Milyen lesz az új jövő, amelyben a kereső nem linkeket tálal, hanem a chatbot által generált szöveget?
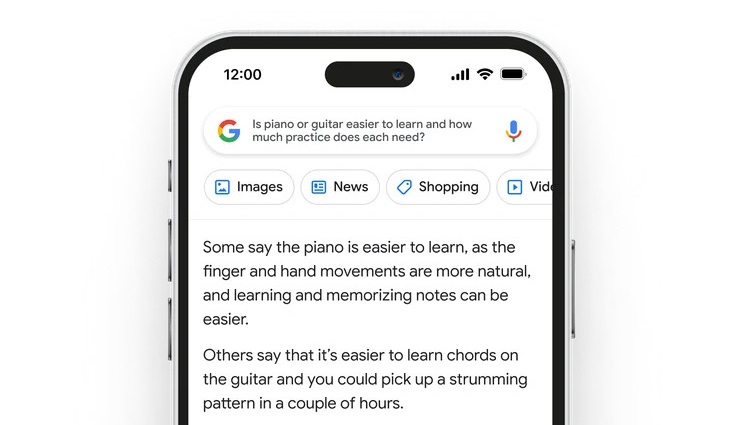
A Google máris bejelentette válaszát a ChatGPT-re: jön a Bard
Heteken belül mindenki hozzáférhet a Google saját chatbotjához, és az első képek alapján rögtön beépítik a funkciót a keresőbe.