Mocskos szexista a Google gépi fordítója, vagy precíz, szabálykövető algoritmus?

Egy olvasójára hivatkozva az Index szerdán azt írta, hogy a magyarra németre való fordításkor a főnök, az orvos, a gazdag és az okos mindig hím-, az ápoló és a szegény viszont kizárólag nőnemű a Google Translate-ben, a cég online fordítójában. Magyarról angolra ugyanez volt az ábra.
A Quartz a törököt és a kínait vizsgálva jutott ugyanerre az eredményre.
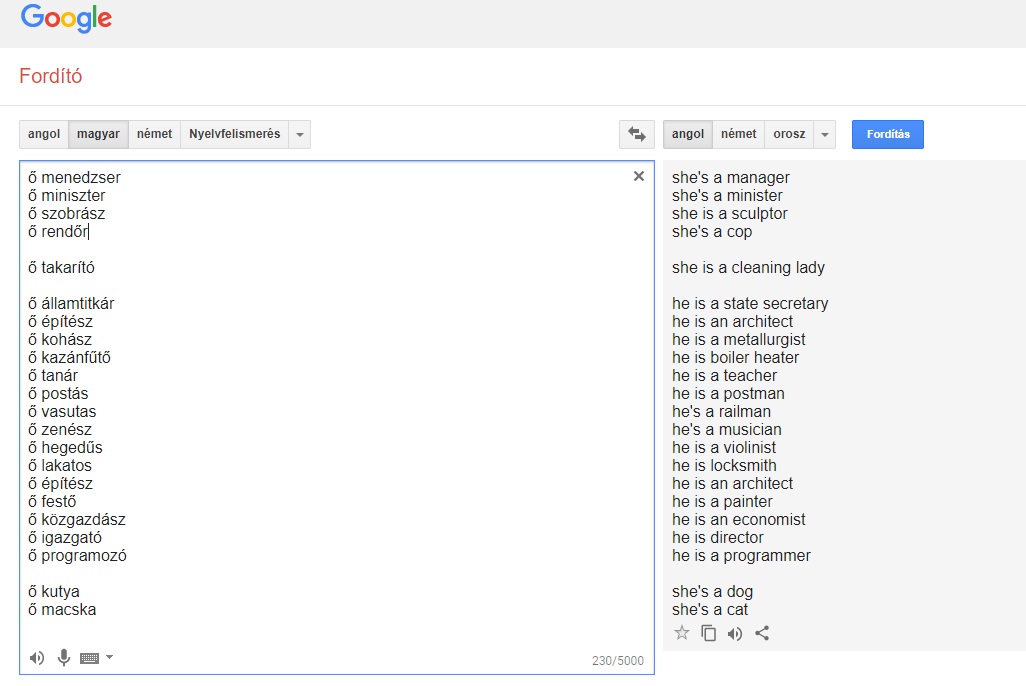
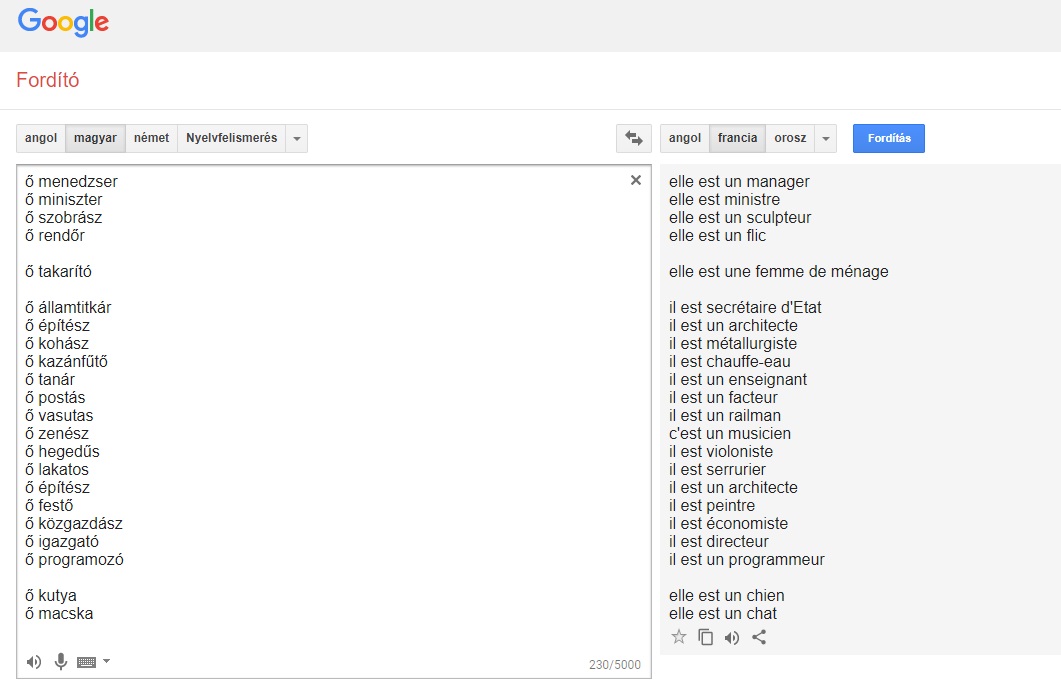
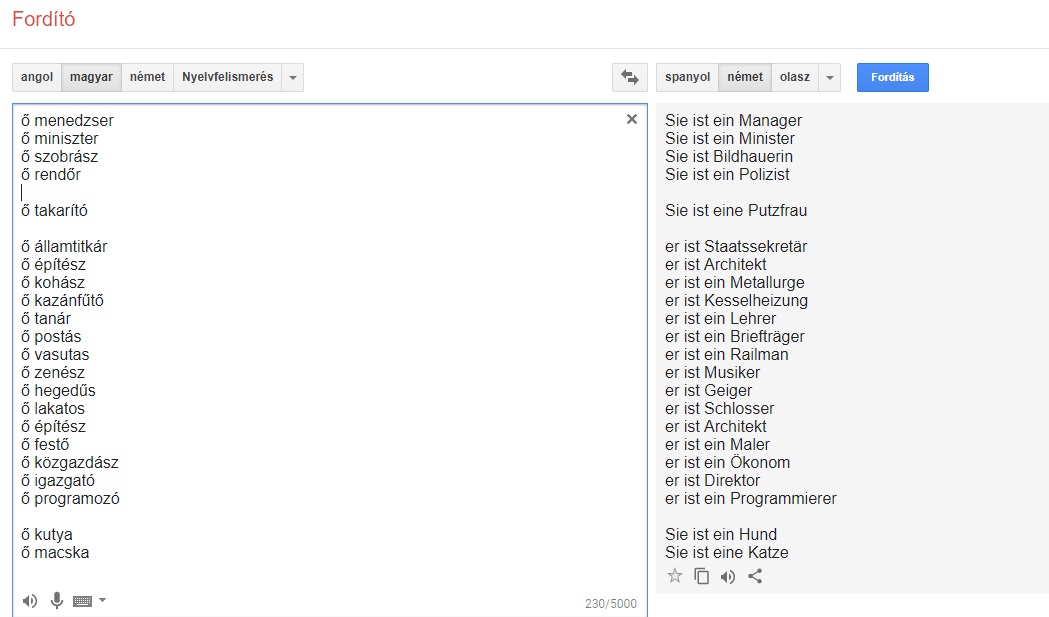
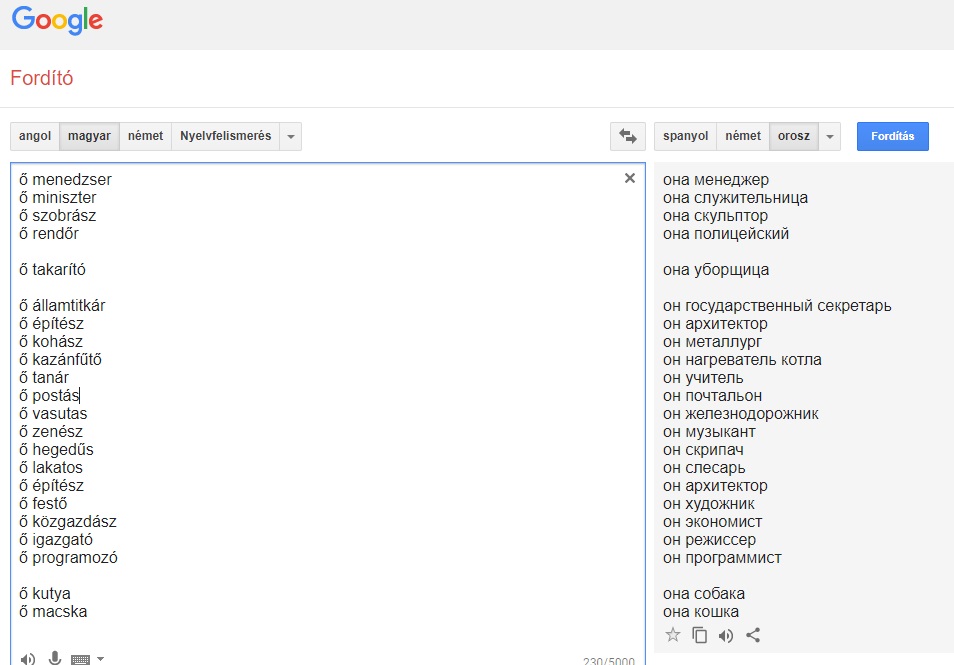
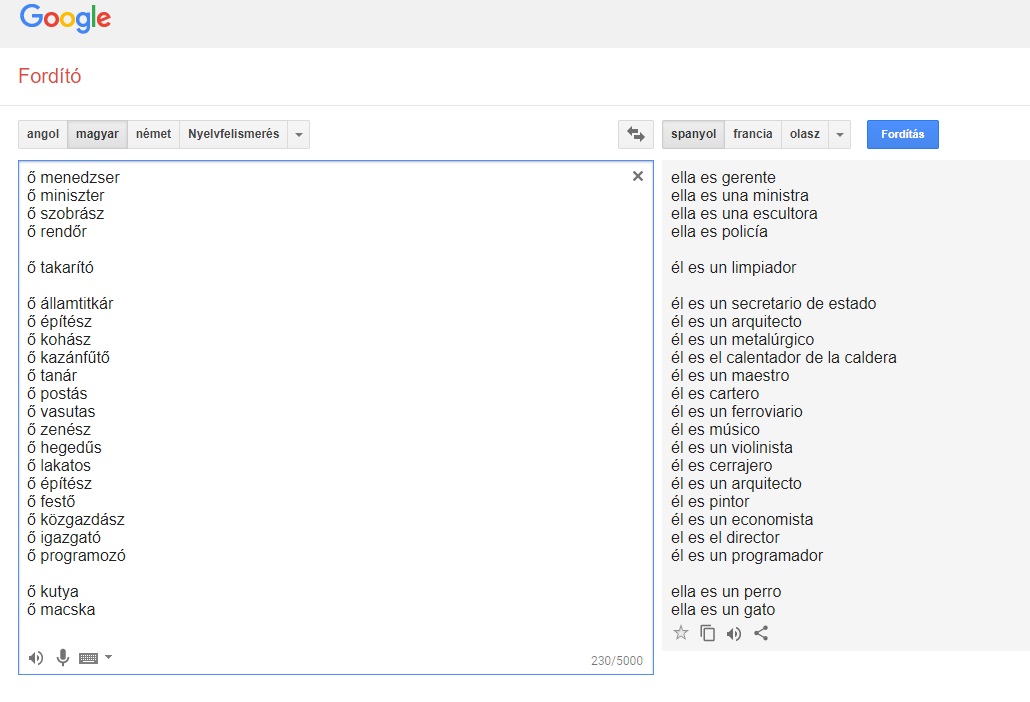
A Qubit a magyarról angolra, franciára, németre, olaszra, oroszra és spanyolra fordításkor is hasonlókat tapasztalt. A többi kísérlethez képest az alábbi eredményekben az a meghökkentő, hogy a Google Translate a menedzser, miniszter, szobrász, rendőr és takarító szavakat magyarról teljesen következetesen nőneműnek fordítja csaknem az összes kiválasztott célnyelvre, míg az államtitkár, az építész, a hegedűs és társaik következetesen hímneműek lesznek az említett hat nyelven. Ezen a listán az egyetlen kivétel a takarító, amit a Google olaszra és spanyolra hímneműnek fordít, angolra, franciára, németre és oroszra viszont nőneműnek. (Ha viszont valaki kutya vagy macska, abból az összes célnyelven nőnemű lesz: she's a dog, elle est un chat, stb.)
A nagyfokú egyezés arra enged következtetni, hogy a Google vagy ugyanazokat a korpuszokat használja a magyarról az említett nyelvekre való fordításkor, ami valószínűtlennek tűnik, vagy mégis létezik egy olyan általános szabály az algoritmusban, ami kimondja, hogy bizonyos szavakat magyarból, ahol a személyes névmás nem utal a nemre, milyen neműnek fordítson angolra, franciára, németre, olaszra, oroszra és spanyolra, ahol viszont bizonyos számban-személyben utal.

A problémát felvető két orgánum azzal nyugtatta olvasóit, hogy az elmúlt években számos tanulmány tisztázta: a platformok működési sajátossága okozza a feltűnő egyenlőtlenséget. Kálmán László nyelvész, az MTA Nyelvtudományi Intézetének főmunkatársa a Qubitnek azt mondta: „A Google-fordító részben statisztikai alapon működik. Nincs nyelvtan, nincsenek szabályok, nincs belső nyelvtani vagy szemantikai reprezentáció, csak az egyik és a másik nyelv korpusza (hatalmas szöveghalmaza) közötti megfelelések vannak”.
Azok között a nyelvek között, amelyeken kevesebb a netes tartalom, még csapnivalóbb a fordítás, mint a jelentősebb online korpusszal rendelkező nagy nyelvek között. Ez az oka egyébként annak is, hogy annál elfogadhatóbb lesz a fordítás, minél hosszabb szövegrészt adunk meg a platformnak, mert a terjedelmesebb kontextus több információt tartalmaz, ez pedig szerepet játszhat az illesztésnél. „Ha tippelnem kell, talán nem közvetlenül megy az egyik nyelvről a másikra, hanem mindig olyan nyelvpárokat választ, ahol a legnagyobb a párhuzamos korpusz. Ha így van, akkor lehet, hogy mondjuk a magyar-angol párnál nagyjából eldől a dolog, és onnan tovább az angol-olaszban már nem nagyon van változás” – mondta Kálmán.
Nem tökéletes, de elfogadható kompromisszum
„Mint sok más facebookos, twitteres fezúdulás és felfedezés esetében, a probléma nem új – persze a fake news korában már azt is meg kell becsülni, ha egy hír igaz, de régi” – írja Orbán Katalin, az ELTE Média és Kommunikáció Tanszékenek adjunktusa. A tanszék Eperbombázó címen elérhető blogján Orbán kifejti, hogy a korpuszok összevetése 2016-tól a Google-nál kiegészült a neurális gépi fordítással. (A Google Translate magyar modulja viszont csak idén áprilistól állt át a neurális hálózat használatára, első ránézésre meglepően jó eredménnyel.)
Érti is, amit fordít?
Orbán szerint a tanulásra és fejlődésre képes mesterséges idegsejt-háló kifejezések helyett „már egész mondatokat dolgoz fel, a szavakat részekre bontja és ezeket a neurális hálózatban egyre inkább képes jelentésekké kombinálni, azaz nemcsak lefordítani, hanem érteni is, amit fordít”. A mesterséges idegsejt-háló Orbán szerint nem olcsó dolog – a Google Brain óriási anyagi befektetésére volt hozzá szükség, és még ez is csak egy viszonylag kicsi gépi agyat eredményezett. „A gépi deep learning segítségével fantasztikus fejlődést láttunk az elmúlt néhány évben, az unaloműző viccparádénak használt Google Fordító, ha nem is megbízható, de használható eszköz, elfogadható kompromisszum lett milliók számára.”
A hímsovinizmus vádjáról Orbán Katalin a témát genderalapon kiveséző 2012 stanfordi kutatást idézve azt írja, hogy a hímnemű névmás azért a gépi fordítóprogramok alapbeállítása, mert felül van reprezentálva azokban a nagy szövegkorpuszokban, amelyekkel a modern rendszereket betanítják. Tehát amikor a legvalószínűbb megoldást keresi a minták között, valószínűbb a felülreprezentált változat. De bizonyos összefüggésekben a nőneműt választja, mert statisztikailag ő takarít, főz, vigyáz a gyerekekre.
Ráadásul, a rendszer mostanáig csak az adott mondatot dolgozta fel, vagyis hiába derült ki az előző mondatokból, hogy férfiről vagy nőről van szó. A legelemibb kontextust nem tudta kezelni, de az összes rejtett részrehajlást megtalálta.
Előítélet helyett gyakoriság
„Előítéletekről szó sincs, csak gyakoriságokról. Hogy a főnök hímnemű, az nem elfogultság, nem előítélet, nem hímsovinizmus, hanem szimpla megfigyelés, statisztikai tény – mondta Kálmán. – Az más kérdés, hogy a Google megtehetné (nemcsak ezekben az esetekben, hanem úgy általában), hogy több lehetőséget is felkínál (he/she). Például egy csomó nyelven a nő, asszony, feleség jelentésű szavak egybeesnek (woman, Frau, stb.), a Google mégis mindig csak az egyiket, nyilván a leggyakoribbat dobja fel.”
Orbán Katalin blogbejegyzésében kitér arra, hogy idén augusztusban Helsinkiben egy neurális fordítórendszer átsettenkedett a mondathatáron. Azt tesztelték vele az OpenSubtitles többnyelvű feliratain, hogy mi történik, ha a szomszédos mondatokkal együtt kezeli a fordítandó mondatot. Ez alkalmas lehet arra, hogy jobban megfejtse és alkalmazza a nemre vonatkozó információt is.
A tanszéki blog összegzése szerint a statisztikai alapú hibás és sztereotip módon elfogult fordítás csak egy példája annak, ahogy a mesterséges intelligencia az adatok mintáiból kiindulva az előítéleteket is átveszi. Ez a torzító hatás érvényesül a pellengérre állított fordítóplatformnál. A felülírás helyett a mintákon lehetne változtatni, mert, mint Orbán kifejti, a mesterséges intelligencia előnye ez esetben hátránya is. Nem definíciókra és szabályokra épül a működése, hanem felfoghatatlan mennyiségű adatból megtanult kapcsolatok és minták alapján ad elég jó tippjeket.
