Mi az a kollokáció, és hogyan fordítsa a gép angolra, hogy „bakot lő”?

Kedves olvasóink, emlékeztek még a teknőcös-entrópiás példákra? (Mellékesen megjegyzem: tessék nyugodtan teknősbékának hívni, legalább a 14. század óta bevett szó ez, és ha valaki szerint mégis „helytelen”, annak üzenem, hogy a bazsarózsa sem rózsa, meg a tubarózsa sem, de még a pünkösdirózsa sem. Ott egye meg a fene, aki ezek helyett a latin nevüket használja, csak kötelezővé ne tegyék.) Sokakban felvetődött, még levelet is kaptam róla, hogy mi a gyakorlati jelentősége ennek a módszernek, hogy nem lehetne-e valami ütős példával bemutatni a használatát. Ezért most mutatok egy érdekes használati területet, a nyelvtechnológiából, az úgynevezett kollokációk azonosítását.
Hogy mi is az a kollokáció, az elég vitatott kérdés. Vannak, akik minden olyan többszavas kifejezést így hívnak, ami nagyon gyakori, szokványos, például azt is, hogy dolgozni megy, meg azt is, hogy bakot lő, meg azt is, hogy romokban hever. Pedig az első egyszerűen csak gyakori, de semmi szokatlan nincs benne, teljesen transzparens a jelentése, vagyis világos, hogy hogyan jön ki a jelentése a részeiből, míg a második kettő nem ilyen. A bakot lő pont az ellenkezője, hiszen amikor ezt tesszük, annak általában se a bakhoz, se a lövéshez semmi köze. Az ilyen kifejezéseket a nyelvészek idiómának nevezik. Végül a romokban hever kifejezést talán megérti az is, aki sosem hallotta (a bakot lő-ről ezt nem lehet elmondani), de magától nem jutna eszébe, hogy ezt így kell kifejezni. Ezért ezt szakszerűen produkciós idiómának nevezik, de van olyan is, aki csak ezt az alesetet nevezi kollokációnak.
Shooting bucks, avagy baklövészet
A nyelvtechnológiában nyilván fontos a kollokációkat azonosítani, legalábbis a kevésbé transzparens fajtái nyilván fontosak, például a számítógépes, automatikus megértés szempontjából, mert ezek azok, amiket nem lehet „szó szerint” megérteni. Az más kérdés, hogy például a gépi fordítást sokszor megértés nélkül próbálják megoldani, pusztán statisztikai alapon. Például a bakot lő kifejezésnek egy jó nagy korpuszban számtalan angol megfelelője lehet, de gyakorlatilag egyikben sincs szó `bakról' (buck) meg `lövésről' (shoot) – leggyakrabban olyasmit találunk, mint make a mistake. (És legyünk optimisták: ha a szövegkörnyezetből kiderül, hogy mondjuk vadászatról van szó, akkor még az is lehet, hogy a fordító abban a környezetben valószínűbbnek fogja találni a shoot a buck fordítást.) De még a statisztikai alapú értelmezést is segítheti, ha megtaláljuk a kollokációkat, és ezt pont olyan eszközökkel szokták végezni, mint amiket a kiagyalt teknősbékás példán bemutattam.

Vegyük az egyszerűség kedvéért azt az esetet, amikor csak szópárokat nézünk, közvetlenül egymás után álló szavakból. „Szón” most olyan betűsort értek, amin belül nincsenek betűközök és írásjelek, az elején és a végén viszont ilyenek vannak. Én a Magyar Nemzeti Szövegtár korpuszából végeztem mindenféle gyűjtést ennek a kísérletnek az elvégzéséhez. Megint azt fogjuk vizsgálni, hogy mennyivel járunk jobban, ha két jelenséget együtt tekintünk, mint ha külön-külön. (A részletes számításon most már nem megyek végig, a korábbi írásomban leírtam, hogyan kell elvégezni.) Legyen a két jelenség az, hogy az első szó a romokban szó-e, vagy nem, a másik jelenség meg az, hogy a második szó a hever szó-e, vagy nem:
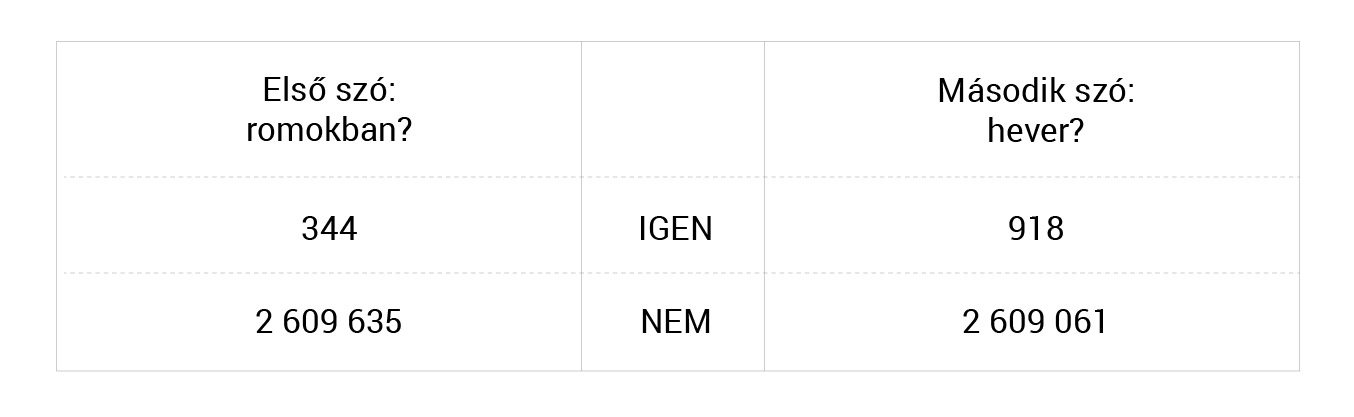
Körülbelül 2.5 millió (pontosan 2609979) szópárt néztem meg. Kiszámoltam, hogy az első rendszer entrópiája 0,0019, a másodiké pedig 0,0045, az összesen 0,0064. És most nézzük meg a két rendszert együtt:

(Itt az X azt jelenti, hogy „nem a romokban szó”, az Y pedig azt, hogy „nem a hever szó”.) Ennek a rendszernek az entrópiája 0,0057. A nyereség 0,0007 bit, ami körülbelül 11 százalékot jelent. Ezt nyugodtan megszorozhatnánk kettővel, mert a legnagyobb lehetséges együttjárásnál (amikor a két szó kizárólag egymás mellett fordul elő) a nyereség 50 százalék (tessék utánaszámolni!). Egyébként a 8-10 százalék körüli nyereség már majdnem mindig megszilárdult kifejezésre utal.
Az érdekesség kedvéért megnéztem még három szópárt, egy sokkal nagyobb korpuszban (kb. 75 millió szópár):
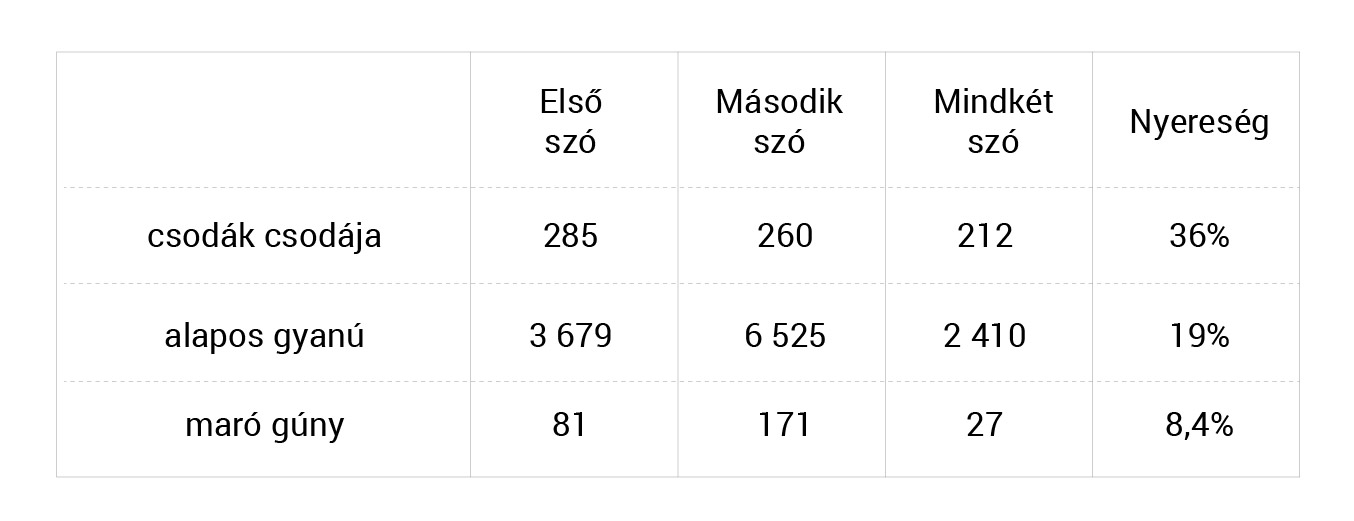
Mindez nagyon szép, de az eredményekkel csaltam abban az értelemben, hogy csak olyan példákat választottam itt ki, amik valamilyen értelemben tényleg kollokációnak minősülnek. Az eredménybe rengeteg „szemét” is bekerült, és ezeknek a kiszűrése lenne a legnehezebb feladatat. Például igen nagy (45 százalékos) volt a nyereség olyan kifejezéseknél, mint tudatjuk mindazokkal (gyászjelentésekben igen gyakori), vagy például a bérlemények elidegenítése (38 százalék) vagy az eladandó részvénycsomag (36 százalék), amikben semmi idiómaszerű sincs, és valószínűleg semmilyen nyelvben nincs is rájuk egyetlen szó.
Ez a fajta kollokációkeresés tehát jó móka, és hasznos is, de nagyon sok „hamis pozitív” eredményt ad, tehát valószínűleg még sok más vizsgálattal kellene kiegészíteni. Nem beszélve arról, hogy nehéz is mérni, mi számít igazi, és mi fals pozitívnak. Például a munkába megy vajon milyen mértékben kollokáció (vagy akár idióma)? Elvileg úgy is lehetne, hogy a magyarban ennek munkához megy vagy munkára megy lenne a szokásos kifejezése (vagy hogy csak dolgozni megy-nek lehetne mondani), ebből a szempontból tehát kénytelenek lennénk kollokációnak tekinteni. (Az én korpuszomban egyáltalán nem minősült annak, még a munkába áll esetében is csak 1% körül volt a nyereség.)
Lehet, hogy arra kell jutnunk, hogy szinte minden, amit mondunk, kollokációszerű, kivéve, ha nagyon eredeti, szinte költői nyelven fogalmazunk.
A szerző nyelvész, az MTA Nyelvtudományi Intézetének főmunkatársa.

A rend ára
Hogyan mérhetjük meg a nyelvészetben, hogy mekkora az ára a rendetlenségnek? Vagy ami ugyanaz: a rendrakásnak? Mennyi információt hordoz a szóköz, és hány biten lehet eltárolni egy teknős útját?