Szintet lépett a mesterséges intelligencia: először tanult meg sakkozni egy AI emberi segítség nélkül

Nagy utat jártunk be a stratégiai táblajátékok és a számítógépek közös történetében, mióta Alan Turing 1947-ben megalkotta az első számítógépes sakkprogramot, vagy mióta az IBM gépe, a Deep Blue 1996-ban elsőként vert meg emberi sakkvilágbajnokot, a játékot 1985 és 2000 között uraló Garri Kaszparovot.
Mivel sakkban már egy PC-n futtatható program is képes legyőzni a legnagyobb játékosokat, más játékok felé irányult a figyelem. A Google mesterséges intelligenciával (AI) foglalkozó műhelye, a DeepMind 2014-ben fejlesztette ki az AlphaGo nevű programot, amelyet a nevében is szereplő ősi kínai játékkal, a stratégiai lehetőségekben meglehetősen gazdag góval ismertettek meg. A program algoritmusa gépi tanulási és fabejárási technikákkal edződött, hónapok alatt a legfejlettebb goprogrammá vált, 2015 októberében pedig elsőként vert meg előnykő nélkül profi emberi gojátékost.

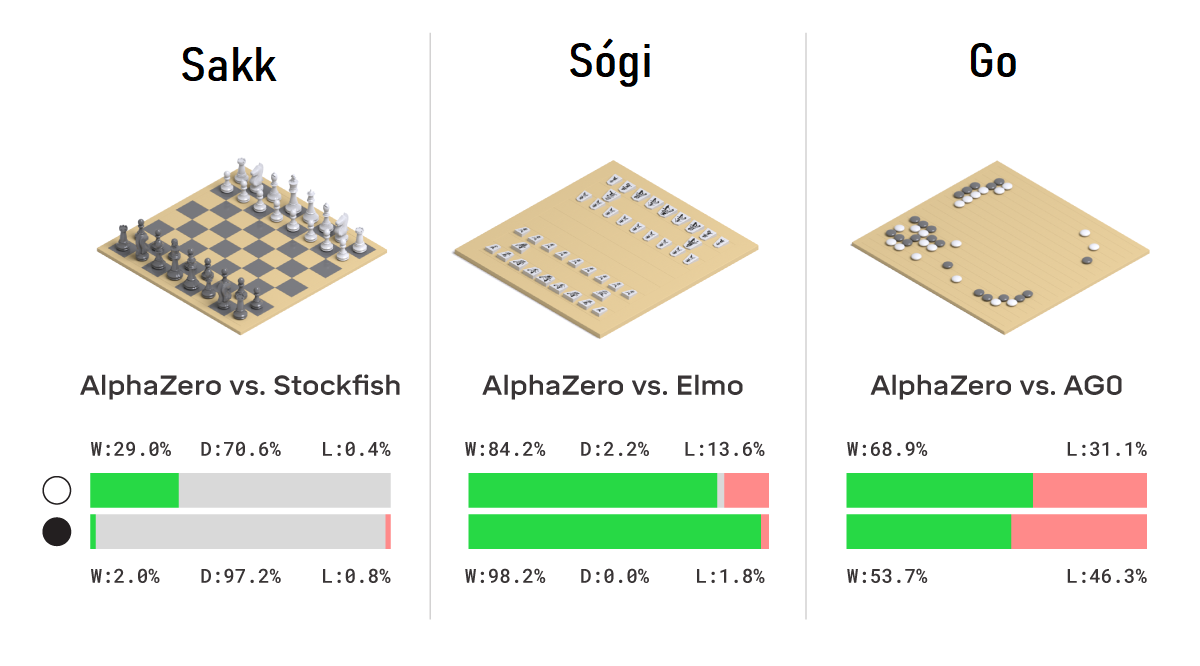
Most egy még újabb mérföldkőhöz érkeztünk: az AlphaGo kevésbé specializált, de hasonló alapokon nyugvó utódja, az AlphaZero néhány órányi tanulás után három játék (sakk, go, sógi) regnáló gépi játékosát is legyőzte, méghozzá úgy, hogy a játékszabályon kívül semmit sem tápláltak bele előre, vagyis minden lépés az algoritmus saját kreativitásán, improvizációján múlt. Az egyéves eredmények részleteit a Science folyóiratban közölték.
- Sakkban a Stockfish nevű nyílt forráskódú sakkprogrammal, a jelenlegi gépi világbajnokkal játszott az AlphaZero, amely 1000 játszmából 155-öt megnyert, 6-ot elveszített, a maradék 839 esetben pedig remiztek a felek.
- Sógiban simán lealázta a világbajnok programot az AlphaZero: az Elmo ellen a játszmák 91,2 százalékát megnyerte.
- Góban pedig házon belül zajlott a csata, de az AlphaZero még így is 61 százalékos győzelmi mutatót tudott összehozni a specializált programmal, az AlphaGóval szemben.
„Nem tudom leplezni az elégedettségemet, hogy olyan dinamikus stílusban játszik, mint amilyen az enyém. Az általános megítélés az volt, hogy a gépek végtelen, száraz manőverezéssel próbálják meg elérni a tökéletességet, általában döntetlent eredményezve. Ehhez képest én úgy láttam, hogy az AlphaZero a figurák aktivitását részesíti előnyben az anyaggal szemben, ami olyan pozíciókhoz vezet, amelyek az én szememnek kockázatosnak és agresszívnek tűntek” – állította Garri Kaszparov a Science-be írt cikkében.
Most már a nulláról tanulnak a gépek
Korábban úgy programozták a játékos AI-programokat, hogy azokkal emberi játszmák millióit elemeztették, vagyis a lehetséges lépések közül már rengeteget ismertek a gépek, mire eljutottak oda, hogy ki kellett állni egy ember ellen – ráadásul ezeket csak egy-egyféle játékra lehetett használni. Az AlphaZero ezzel szemben mindössze egy mély neurális hálóval rendelkezik, az algoritmusába pedig a játékszabályokon kívül semmit sem ültettek.
Ahhoz, hogy az AlphaZero elsajátítson egy játékot, a megerősítéses tanulás módszerével több millió játszmát kell lejátszania önmaga ellen, az ezekből levont tanulságok (jó és rossz lépések, győzelmek, vereségek, döntetlenek) alapján kialakít egy stratégiát, amit betáplál a neurális hálózatába. A tanulási idő a játék komplexitásán múlik: a sakkhoz 9 órára, a sógihoz 12 órára, a góhoz 13 napra volt szüksége.
Ennek a tanulási módszernek olyan meglepő eredményei vannak, amit a legtapasztaltabb játékosok is ámulattal néznek. „Néhány lépése, mint például amikor a királyt a tábla közepére mozgatja, ellentmond a sógi játékelméletének és emberi szemszögből nézve veszélyes helyzetbe sodorja az AlphaZerót. De hihetetlen módon irányítás alatt tartja a táblát. Az egyedi játékstílusa azt mutatja, hogy vannak még újfajta lehetőségek a játékban” – nyilatkozta a DeepMind blogján Habu Josiharu, a sógi történelmének legsikeresebb játékosa.
A megszokott fabejárási módszerrel, az MCTS nevű keresési algoritmussal a Stockfish másodpercenként 60 millió lehetőség közül választja ki az ideális lépést, ehhez képest az AlphaZero a mennyiség helyett a minőségre megy, és az óriási adatmennyiség helyett szűkebb halmazból (60 ezer pozíció) választja ki a legmegfelelőbb lépést. A DeepMind szerint egy-egy lépés előtt a Stockfish 10 millió, az AlphaZero 10 ezer, egy emberi sakkmester pedig körülbelül 100 lehetséges lépés között mérlegel.
„Van egy nagyon finom intuitív érzéke, ami segít neki egyensúlyozni a sokféle tényező között. A neurális hálózatában több milliónyi hangolható paraméter van, mindegyik a saját módján tanulja meg, hogy mi a jó a sakkban, és amikor mindezt egyszerre használja, az az agyunkhoz hasonló módon tükrözi az emberi képességet, amivel mérlegelés után azt mondjuk, hogy igen, ez lesz a jó lépés” – mondta a Telegraphnak a DeepMind megerősítéses tanulást felügyelő kutatója, David Silver.
Silver hozzátette:
„A személyes véleményem az, hogy valamiféle fordulóponthoz érkeztünk, ahol elkezdjük megérteni, hogy sok olyan képesség, mint az intuíció vagy a kreativitás, amiket eddig az emberi elmével társítottunk, valójában elérhető a gépi tanuláson keresztül is. Azt gondolom, ez egy nagyon izgalmas történelmi pillanat.”
Az előző mérföldkő Kína paradigmaváltásához vezetett
Az AlphaGo filmen is megörökített diadala óriási szenzáció volt, köszönhetően annak, hogy egy gojátszma során a tábla lehetséges állásainak száma 2 x 10^170, vagyis több mint a megfigyelhető világegyetem összes atomjának száma. Az első győzelem után a DeepMind kihívta a legmagasabb szintű, 9 danos dél-koreai gojátékost, az eleinte szkeptikus I Szedolt, aki miután 4-1-re kikapott az AlphaGótól, élete legnagyobb eredményének nevezte, hogy egy játszmában sikerült nyernie.
Az egyik legnagyobb dél-koreai napilap, a Csungang Ilbo gorovatának vezetője így nyilatkozott I Szedol vereségének másnapján: „Szomorú volt a tegnap este. Sokan alkoholt is ittak. A koreaiak attól félnek, hogy a mesterséges intelligencia elpusztítja az emberi történelmet és kultúrát”. A koreai goszövetség tiszteletbeli 9 danos címmel jutalmazta az AlphaGót az „őszinte erőfeszítéséért, hogy elsajátítsa a go taoista alapjait és elérje az istenközeli szintet”.

Kínában is óriási hatása volt I Szedol, majd a kínai mester, Ko Csie későbbi vereségének. A New York Timesnak két kormányközeli professzor is arról nyilatkozott, hogy az AlphaGo győzelmei kongatták meg a vészharangot a kínai kormánynál: ezt követően rendelték el az állami pénzek áramlását az AI-kutatásokba, amelyek célja egyfelől a mezőgazdaság, az egészségügy vagy a gyártás segítése lenne, de a központi megfigyelés, az internetcenzúra vagy a bűnmegelőzés és a rakétafejlesztés területén is alkalmazhatónak találták.
Felkészülnek a fehérjehajtogatók
A DeepMind alapító vezérigazgatója, Demis Hassabis elmondta: „A tiszta lappal való indítás azért volt fontos, mert szeretnénk, ha ezek az eredmények olyan általánosak lennének, amennyire csak lehet. Minél általánosabb érvényűek a győzelmek a különböző játékokban, annál nagyobb eséllyel lehet majd a technológiát a valós problémák megoldására átültetni”.
Példaként a fehérjehajtogatást hozta fel, amely állítása szerint kezdetektől fogva a DeepMind egyik legfontosabb célja volt. „Régóta a fejemben van, mivel óriási problémát jelent a biológiában, és számos más területen lehet majd használni, például új gyógyszerek felfedezésében” – mondta Hassabis.
David Silver szerint a huszadik századtól kezdve mindig létezett egyfajta felosztás aközött, hogy mire képesek az emberek, és mire a számítógépek, de ez mostantól változni fog. „Az erőteljes gépi tanulási technikák eljövetelével azt látjuk, hogy elkezdett billegni a mérleg nyelve, és olyan számítógépes algoritmusaink vannak, amelyek képesek nagyon is emberszerű tevékenységeket jól végezni”.