DNS-be illeszthető új nukleotidokat fedeztek fel

A DNS ikonikus kettős spirál formájában annyira összeforrt az öröklődés fogalmával és az ehhez kapcsolódó alkalmazásokkal, hogy ma már talán elképzelni is nehéz, de volt idő, amikor kifejezetten unalmas, érdektelen molekulának tartották.
1868-69 telén egy Tübingenben dolgozó fiatal svájci orvos, Friedrich Miescher a helyi kórház gennyes váladékkal átitatott szöveteit felhasználva, a váladékban fellelhető immunsejtekből izolált egy szürke, paszta állagú anyagot, amiről némi meglepetésre kiderült, hogy egyáltalán nem úgy viselkedik, mint a korábban izolált fehérjék: nem oldódik sós vízben, sem forró ecetben, de még sósavban sem, viszont más fehérjékkel ellentétben a szén, az oxigén és a nitrogén mellett jelentős mennyiségű foszfort tartalmaz. Miescher először nukleinnek nevezte el a sejtmagokból származó furcsa anyagot, majd annak sav jellegét kimutatva módosította az elnevezést nukleinsavra.
Később Albrecht Kossel ismerte fel, hogy a nulkeinsavak öt alapvető egységből épülnek fel, ezek az adenin (A), a citozin (C), a guanin (G), illetve a timin (T) és az uracil (U) – utóbbi kettőről ma már tudjuk, hogy egymás analógjai, de míg előbbi csak DNS-ben, utóbbi csak RNS-ben fordul elő. Mindez sokak szemében teljesen alkalmatlanná tette a nukleinsavakat az örökítő anyag szerepének betöltésére, szerintük ugyanis ennek a pár komponensnek a sokszoros ismétlődése nem képes komolyabb információt kódolni. Ezért jobb esetben is csak a kromoszómák vázának tekintették ezt a furcsa anyagot, de maga Mieschner is inkább foszforraktárként gondolt rájuk.
Lehetne kétszer olyan izgalmas is
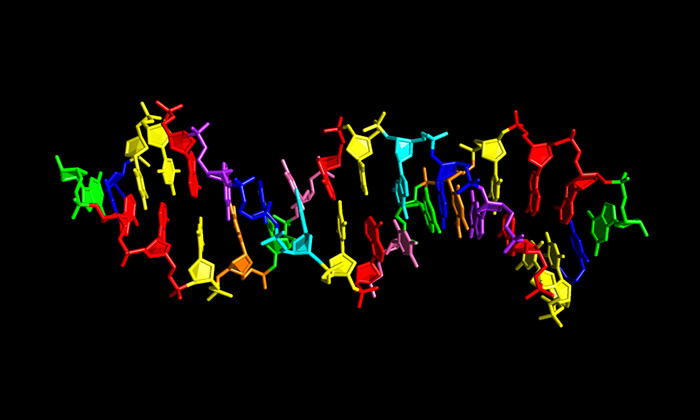
Most, 150 évvel Mieschner felfedezését követően (és durván hét évtizeddel az után, hogy bebizonyosodott, az „unalmas” DNS valójában egyáltalán nem az, sőt mindenféle tulajdonság elsődleges örökítőanyaga), kiderült, a DNS kémiai összetétele valójában lehetne kétszer annyira is izgalmas, mint ahogy eddig ismertük. Az eheti Science egyik cikkében Steven Benner csoportja négy új nukleotidot írt le, amelyek sikeresen beilleszthetők a DNS-be, és jelenlétükben is kialakulhat az a bizonyos kettős spirál.
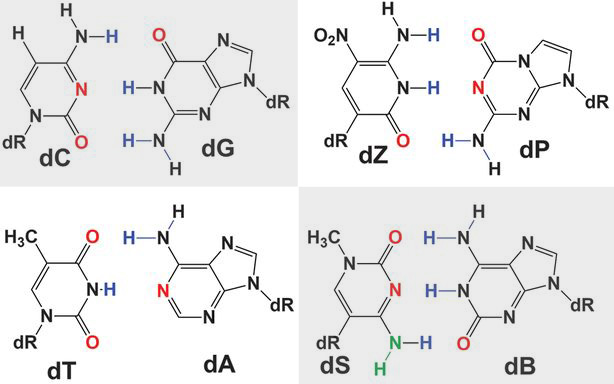
Az új, szintetikus bázisok, S, B, Z és P (vagy hivatalos neveiken: S = 3-metil-6-amino-5-(1′-β-D-2′-deoxiribofuranozil)-pirimidin-2-on, B = 6-amino-9[(1′-β-D-2′-deoxiribofuranozil)-4-hidroxi-5-(hidroximetil)-oxolan-2-il]-1H-purin-2-on, Z = 6-amino-3-(1′-β-D-2′-deoxiribofuranozil)-5-nitro-1H-piridin-2-on és P = 2-amino-8-(1′-β-D-2′-deoxiribofuranozil)-imidazo-[1,2a]-1,3,5-triazin-[8H]-4-on) hasonló szerkezetűek, mint hagyományos társaik, és az A:T és G:C párosokhoz hasonlóan maguk is párokba szerveződnek. Ezeknek az S:B és Z:P párosoknak a jelenléte alapvető feltétele nemcsak a DNS stabilitását kialakító spirálos struktúra kialakításának, hanem annak is, hogy a DNS-ben levő információ másolható legyen akár egy új DNS-szálra, akár RNS-re.
Érdekes módon ahhoz, hogy a nyolc bázist tartalmazó, a japán hacsi (nyolc) és modzsi (betű) szavak alapján hacsimodzsi DNS-nek nevezett nukleinsavszálról RNS készüljön, nem is volt szükség új enzimekre, hanem elég volt minimálisan módosítani egy bakteriális fehérjét, ami ezután nagy pontossággal tudta a folyamatot katalizálni.
Bennerék kísérlete egyrészt nagyban alátámasztja a DNS szerkezetét feltáró, majd a genetikai kód megfejtésében is éllovas szerepet játszó Francis Crick most már évtizedes elméletét, amely szerint az A, C, G, T bázisok szerepe a genetikai kód kialakításában egy „befagyott véletlennek” tekinthető, aminek nincs komolyabb szerkezeti oka, csak egyszerűen annyi, hogy ezek a bázisok áltak a rendelkezésre az élet kialakulásakor (és nem mondjuk az S, B, Z, P négyesfogat).
Az elméleti megfontolásokon túl pedig közvetlenebb haszon, hogy 8 bázissal sokkal több információt lehet a DNS-ben tárolni. Ennek egyelőre az lehet a következménye, hogy a DNS-t adathordozóként használó eljárások még nagyobb lendületet kaphatnak, és még bonyolultabb, szofisztikáltabb algoritmusokkal még kisebb helyen, még nagyobb pontossággal tudnak majd információt tárolni. Ha kötözködni akarunk, persze fontos megjegyezni, hogy míg azt tudjuk, hogy a klasszikus DNS – egyes, ma már jól ismert változásoktól eltekintve – évezredeken át viszonylag pontosan meg tudja őrizni az információt, arról nincs és nem is lehet tudomásunk, hogy a hacsimodzsi DNS-t hogyan állja majd az idő próbáját.
És ott van a még mindig kicsit sci-fi-be illő, távlati lehetőség, hogy a „nem standard” nukleotidokkal „nem standard” aminosavakból álló, teljesen új funkciójú fehérjéket lehessen kódolni (a természetben előforduló fehérjék jelenleg 22 aminosavat tartalmaznak, de laboratóriumi körülmények között jóval több aminosavat sikerült már előállítani). Ez azonban jóval nagyobb falat lesz, mint az extra négy bázispár beépítése a DNS-be. A sikeres fehérjeszintézishez egy nagyon sok faktorból álló molekuláris gépezetre van szükség, amelyet adaptálni az új bázisok felismeréséhez és az új aminosavak beépítéséhez nem ígérkezik könnyű feladatnak. A nehéz persze nem ugyanaz, mint a lehetetlen, így meglátjuk, mire jutnak.
A szerző genetikus, Qubiten megjelent korábbi cikkei itt olvashatók.
Kapcsolódó cikkek a Qubiten:
Az örökítőanyagod akkor is árulkodik rólad, ha soha nem csináltál DNS-tesztet
Az egyre olcsóbb DNS-tesztek korában legszemélyesebb adatunk, saját genomszekvenciánk is sokkal nyilvánosabb, mint gondolnánk vagy szeretnénk – még akkor is, ha személy szerint soha nem használunk ilyen teszteket.

Megfejtették a ráknak is ellenálló fehér cápa szuperképességeinek titkát
Az eddigi hiedelemmel ellentétben a nagy testű élőlények nem lesznek könnyebben rákosak, de a fehér cápa genomjának feltárása rámutatott arra is, hogyan tudnak akár napok alatt begyógyulni az állat óriási sebei.

A nagy genetikai őskeresés
Mik vogymuk, magyarok? Hunok, avarok vagy egy genetikai konglomerátum? Egyre több adat kerül elő a honfoglalók és az őslakos avarok genetikai összetételéről. De ki az a mitokondriális Éva, és mi köze az Y kromoszómás Ádámhoz?
