Több mint ezer nyelvet képesek felismerni és reprodukálni a Meta Újszövetségen tanított algoritmusai

Több mint ezerféle nyelvet felismerő és reprodukáló mesterséges intelligenciára épülő modelleket épített a Facebook, az Instagram és a Whatsapp tulajdonosa, a Meta – írta hétfőn az MIT Technology Review. Ez tízszerese a jelenlegi nyelvfelismerő algoritmusok kapacitásainak, és így lehetővé válhat olyan nyelvek megőrzése is, amelyek jelenleg a kihalás szélén állnak.
A Meta, amely hétfőn rekordösszegű (1,3 milliárd dolláros) bírságot kapott adatvédelmi gyakorlata miatt az ír adatvédelmi hivataltól, a GitHub közösségi szoftverfejlesztő oldalon keresztül bárkinek elérhetővé teszi a modelleket. Azzal pedig, hogy nyílt forráskódúvá teszi őket, a cég segítani akar a fejlesztőknek abban, hogy gyakorlatilag bármilyen nyelven új üzenetküldő szolgáltatásokat, virtuális valóságra alapuló rendszereket építsenek.
A világon mintegy 7000 nyelvet beszélnek az emberek, a jelenlegi beszédfelismerő modellek azonban mintegy százzal tudnak érdemben dolgozni. Ez azért van így, mert ezeket a modelleket rengeteg jól felcímkézett bemeneti adat segítségével tanítják, ilyen adathalmaz pedig csupán a nyelvek töredéke esetén érhető el – ilyen az angol, a spanyol vagy a kínai.
A Meta fejlesztői úgy kerülték ki ezt a problémát, hogy a vállalat által 2020 óta fejlesztett mesterségesintelligencia-modellek már hanganyagok alapján képesek megtanulni a beszédmintázatokat anélkül, hogy felcímkézett bemeneti adathalmazok sokaságára, például leiratokra lenne szükségük.
Ezeket a modelleket kétféle adathalmazon tanították: az egyik az Újszövetség és annak 1107 nyelven elérhető fordításának hangfelvételeit tartalmazza, a másik pedig az Újszövetség hanganyagát strukturálatlan, felcímkézetlen formában 3809 nyelven. A fejlesztők a hanganyagot és a szöveges adatokat először átdolgozták, hogy jobb minőségű bemeneti adatokra tudják ráereszteni az algoritmust, amelyet arra terveztek, hogy összepárosítsa a hangfelvételeket a szövegekkel. Majd ezt a folyamatot megismételték egy másik algoritmussal, amelyet már az összepárosított adatokon tanítottak.
A kutatók szerint a modelljeik jelenleg több mint ezer nyelven képesek kommunikálni és több mint négyezret ismernek fel, és állításuk szerint a rivális cégek modelljeihez – például az OpenAI Whisper beszédfelismerő programjához képest – feleannyit hibáznak.
Azt azonban elismerték, hogy a beszéldfelismerő modelljeikben több az előítélet és az elfogult kifejezés, mint más modellek esetén; igaz, becsléseik szerint csak 0,7 százalékkal több. Ehhez képest Chris Emezue, a Masakhane szervezet kutatója, aki az afrikai nyelvek természetes nyelvfeldoglozását (natural language processing - NLP) végző programok fejlesztésén dolgozik, azt mondja, a vallási szövegek használata eléggé megosztó, a Biblia ugyanis meglehetősen sok előítéletet és tévedést tartalmaz.
Kapcsolódó cikkek a Qubiten:
A Meta forradalmi algoritmusa feltárta a fehérjeuniverzum sötét anyagát
A Facebook anyavállalatának mesterséges intelligenciával foglalkozó kutatói az eddigi módszereknél sokkal gyorsabb fehérjekutató algoritmust hoztak létre, amely egy csapásra 600 millió fehérje háromdimenziós szerkezetét fejtette meg.
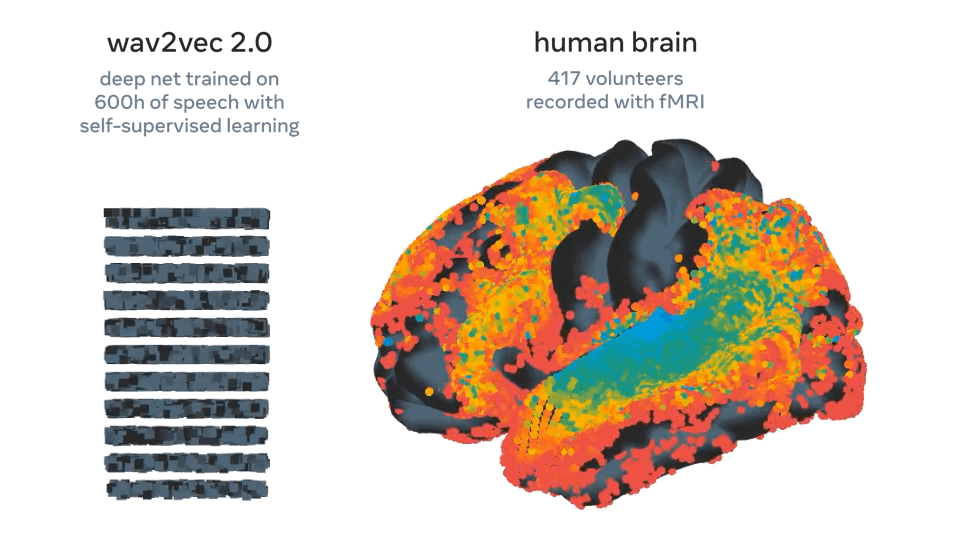
A Meta olyan mesterséges intelligenciát fejlesztett, amely az agyhullámokból találja ki, mit mondunk
A rendszer 73 százalékos pontossággal megjósolta, hogy egy elhangzott beszéd milyen szavakat tartalmazott, és bár korai szakaszában jár a technológia, a legtöbb hasonló megoldással szemben nincs hozzá szükség invazív beavatkozásra.