Douglas Adams megálmodta, Mark Zuckerberg megcsinálta: itt a digitális Bábel-hal

A Mark Zuckerberg-féle Metához tartozó Facebook AI Research (FAIR) kutatói szerdán a világ egyik legrangosabb tudományos folyóiratában, a Nature-ben számoltak be arról, hogy fejlett beszéd- és szövegfordító mesterséges intelligencián dolgoznak, ami a cég más AI-modelljeivel együtt fontos lépést jelent a fikciós Bábel-hal megalkotása felé. A Douglas Adams Galaxis útikalauz stopposoknak című regényében felbukkanó élőlény képes arra, hogy valós időben fordítson két nyelv között, amire a Meta szerint globalizált világunkban egyre nagyobb igény mutatkozik.
A SEAMLESSM4T-nek nevezett AI-modell, amit eredetileg 2023 végén adtak ki, de csak most ismertették részletesen, egyelőre 36 nyelvről, illetve nyelvre képes oda-vissza fordítani. A Nature-ben közölt tanulmány szerint a SEAMLESSM4T teljesítménye lekörözi a korábbi megoldásokét, és azoknál több nyelvet támogat – összesen 100-at. (A részlegesen támogatott nyelvek között a leírás szerint szerepel a magyar is, ami azt jelenti, hogy angolról magyarra működik a dolog, fordítva nem.) A modellt a kutatók és a fejlesztők szabadon letölthetik a GitHubról, és beépíthetik nem kereskedelmi célú alkalmazásaikba is, csak jelezniük kell, hogy a Meta modelljét használják. Ez annak fényében nem meglepő, hogy a Meta AI részlegéhez fűződik az egyik legismertebb, chatbotokat működtető nyílt súlyú (open-weight) nagy nyelvi modell, a Llama 3.1 is.
„Ez a beszédről beszédre fordítás különösen bámulatos, mivel egy végponttól végpontig tartó megközelítést alkalmaz, vagyis a modell direktben képes például angol nyelvű élő beszédet németre fordítani, anélkül, hogy azt először angol szöveggé kellene alakítania, majd átkonvertálnia német szöveggé” – írta a Nature-nek írt véleménycikkében Tanel Alumäe, az észtországi Tallinni Egyetem nyelvtechnológiai laboratóriumának kutatója.
A Meta AI-kutatói közben más modelleken is dolgoznak, amik közül a SeamlessStreaming és a SeamlessExpressive tűnik a legérdekesebbnek. Az előbbi kevés késlekedéssel fordít, az utóbbi pedig megőrzi az eredeti szöveg prozódiáját, vagyis a nyelv olyan, úgynevezett szupraszegmentális tényezőit, mint a hangerő, a hangsúly vagy a hangszínezet. Ha például valaki suttogva mondja angolul, hogy „most altattuk el a babánkat”, akkor a spanyol nyelvű gépi fordító is suttogni fog, ha pedig a beszélő szomorú, a fordítás igyekszik átadni szavainak érzelmi töltetét.
Hogyan működik az új AI-fordító?
A neurális hálón alapuló AI-modellt a szakemberek részben egy önfelügyelt tanulásnak (self-supervised learning), részben egy félig felügyelt tanulásnak (semi-supervised learning) nevezett módszerrel tanították. Ezek a megközelítések Alumäe szerint lehetővé teszik, hogy a modell képes legyen hatalmas mennyiségű nyers adatból, vagyis szövegekből, hangfevételekből és videókból tanulni – anélkül, hogy azokat embereknek kellene kategorizálniuk vagy címkézniük. A modell azon részét, ami a beszéd fordításért felel, a kutatók 4,5 millió órányi, több nyelvű élőbeszéden tanították, aminek az volt a célja, hogy a modell felismerje az adatokban fellelhető mintázatokat.
A szakember szerint a Meta kutatóinak egyik legügyesebb trükkje az volt, hogy a modell tanításához olyan adatokat kerestek a neten, amik különböző nyelvűek, de megfeleltethetők egymásnak – mint például egy francia nyelvű videó, amihez német nyelven készültek feliratok. Azáltal, hogy a modell megtanulta, mikor egyezik meg a két különböző nyelvű szöveg jelentése, 443 ezer órányi, írott szövegnek megfeleltethető hanganyagot tudtak összegyűjteni, majd azt a modell további tanítására felhasználni.
Az AI-fordító az eddig elérhető programok nagy részével ellentétben nem kaszkádszerűen működő alrendszereken alapszik, ahol először egy programrész felismeri a beszédet, egy másik lefordítja az írott szöveget, végül egy harmadik felolvassa azt, hanem közvetlen beszédfordítást kínál. Az ilyen közvetlen fordítórendszerek teljesítménye a Meta kutatói szerint korábban elmaradt a legjobb kaszkád-típusú rendszerekétől. A SEAMLESSM4T ezzel szemben a fordítás minőségét vizsgáló BLEU-teszten a kaszkád-elven alapuló rendszereknél 23 százalékkal magasabb pontszámot ért el a beszédfordítás, és 8 százalékkal magasabbat a beszéd írott szövegre történő fordítása terén. A modell nemcsak jobb minőségű fordítást kínál, hanem jobban tolerálja a háttérzajt és azt is, ha változnak a beszélők.
A Meta kutatói a mesterséges intelligencia felelősségteljes használatára is próbáltak ügyelni: a tanulmányban hosszasan részletezik, hogy miként kísérelték meg kiküszöbölni, hogy a modell a fordítás során az eredeti beszédet „toxikusabbá” tegye (ezt egyének vagy csoportok elleni gyűlöletkeltésre alkalmas kifejezések használataként definiálják). Itt két módszert is alkalmaztak, és sikerült is előrelépéseket elérniük. A másik terület, amit vizsgáltak, a fordítás nemi elfogultsága (gender bias), amit a nyelvtani nem meghatározása során fellépő hibaként definiálnak.
A hagyományos fordítóprogramok, így a Google Translate esetén könnyen előfordul, hogy egy kutatónővel készült interjút úgy fordítja le a program a nemsemleges személyes névmásokat használó magyar nyelvről angolra, hogy a kutatóra sokszor hímnemű angol személyes névmásokkal hivatkozik. Bár ezen a téren a SEAMLESSM4T V2 verziója néhány százalékkal jobban teljesít a korábbi modellekhez képest, a Meta szakemberei szerint további erőfeszítésekre és specifikus eljárások kidolgozására van szükség az elfogultság csökkentéséhez.
De mit tud a gyakorlatban?
A SEAMLESSM4T v2 modellt a Meta oldalán elérhető demó segítségével próbáltuk ki, ami 15 másodpercnyi beszédet képes rögzíteni. Bár a modell támogatott nyelvei között feltüntetik a magyart, a demó sajnos nem ismeri a nyelvünket. Így egy angol nyelvű tesztmondattal próbálkoztunk, és azt fordítottuk le három különböző nyelvre, spanyolra, franciára és németre.
A „nagyon örülök, hogy végre kipróbálhatom az új, egyik nyelvről a másikra történő fordítást lehetővé tevő mesterséges intelligencia modellek képességeit és limitációit” mondatunkat, amit egy csöndes szobában rögzítettünk, a szoftver hibátlanul leírta. Ezután szinte azonnal legenerálta hozzá az írott szöveges és hangalapú fordításokat. Ez nem tűnik nagy dolognak, de néhány évvel ezelőtt sem a helyes átírás, sem a gyors fordítás nem ment volna könnyen.
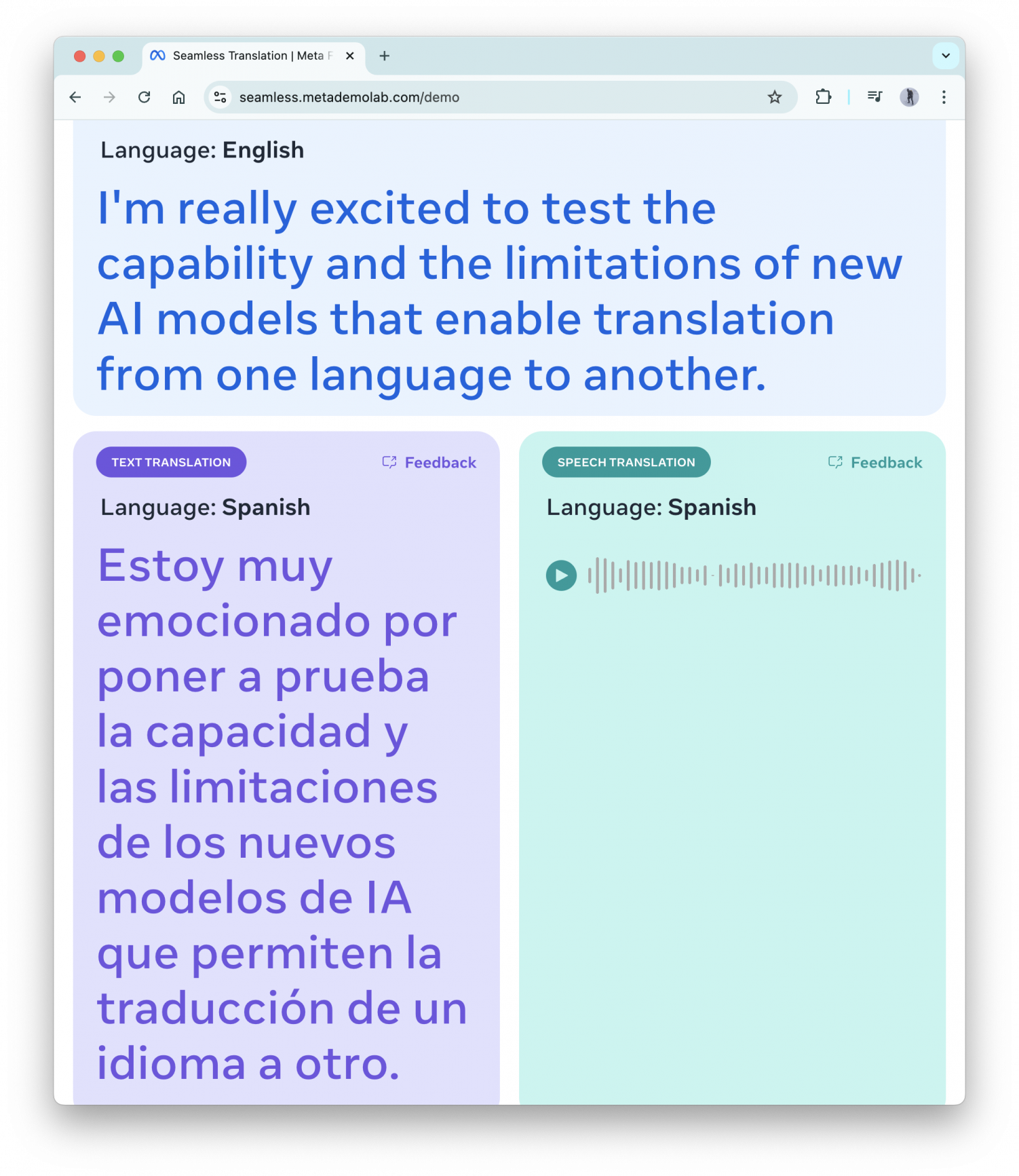
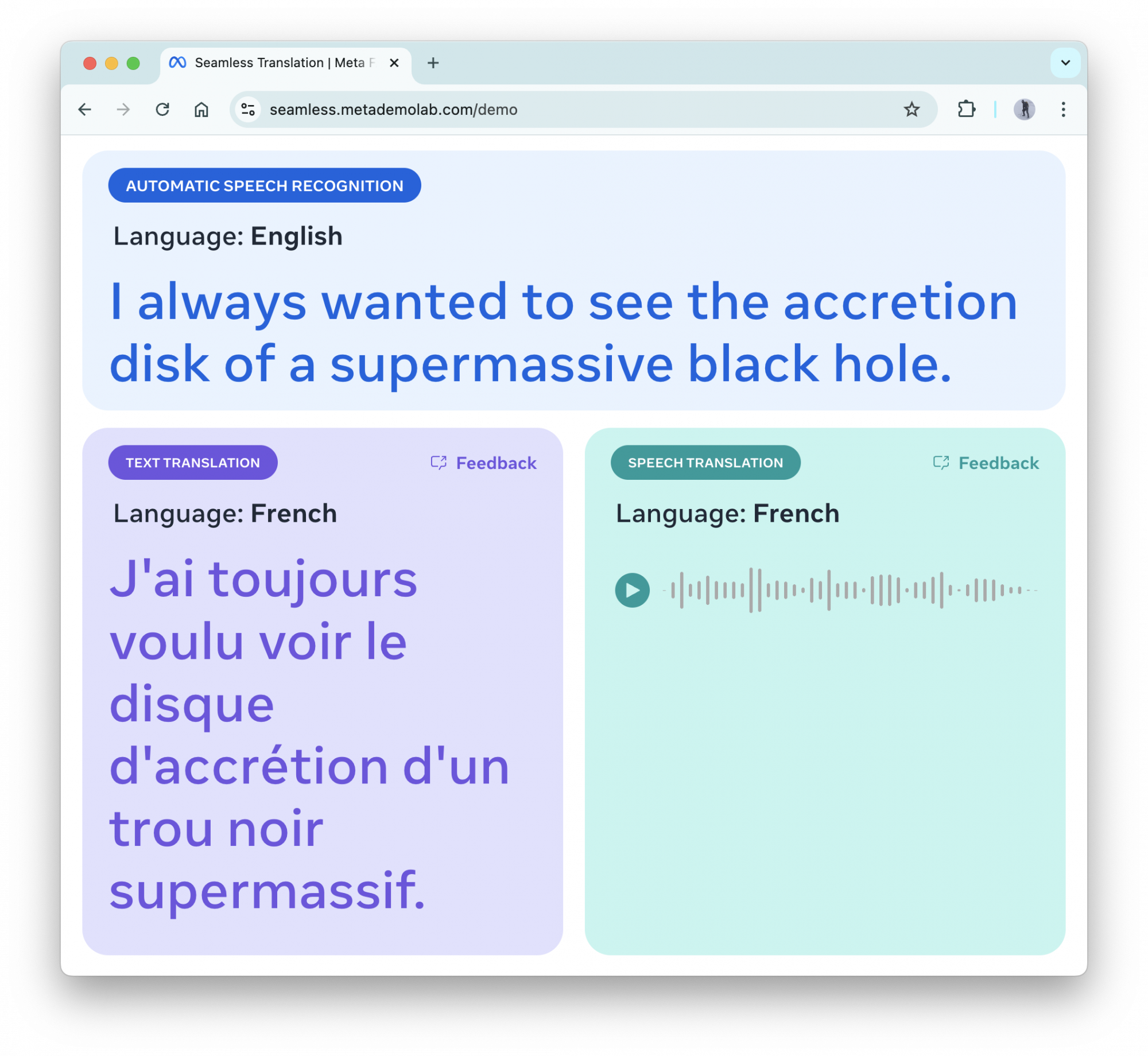
A mondat fordításait a DeepL segítségével ellenőriztük, és azok pontosnak bizonyultak. Ezután arra voltunk kíváncsiak, mit kezd az új modell egy szakkifejezéseket is tartalmazó mondattal, így angolul azt mondtuk neki, hogy „mindig is látni akartam egy szupermasszív fekete lyuk akkréciós korongját” (ez 2019-ben teljesült is). A mondatot ismét hibátlanul leírta és a francia, német, valamint holland fordítás is stimmelt, legalábbis a DeepL szerint.
„Ennek a fejlesztésnek a legnagyobb erénye nem az ötletben vagy a módszerben rejlik, hanem abban, hogy az összes adat és kód, ami a modell futtatásához és optimalizálásához szükséges, publikusan elérhető” – írta Alumäe, hozzátéve, hogy a modell finomhangolható is, vagyis gondosan összeállított adatbázisok segítségével speciális fordítási feladatok elvégzésére optimalizálható.
Bár a szakember szerint elsőre lenyűgözőnek tűnik, hogy a Meta AI-modellje már 100 nyelvet ismer, ez kevésnek tűnik ahhoz képest, hogy világszerte mintegy 7000 nyelvet beszélnek. A technológia másik korlátja, mint írja, hogy egyelőre nem tökéletes zajos környezetben, és meggyűlik a baja az erős akcentussal is. Ennek ellenére szerinte idővel a valós adatok használatán alapuló módszer elvezethet a sci-fiből ismert technológiával vetekedő beszédfordítók megjelenéséhez.
Kapcsolódó cikkek



A Csendes-óceánon vitorlázva mutatkozik csak meg igazán, miért fontos az óceánok és a bolygó védelme
