1561 pályamű közül választottak egy magyar fejlesztést a koronavírus-hackathon legjobb projektjei közé

A #BuildforCOVID19 nevű globális hackathont március 26. és 30. között szervezték meg azzal a céllal, hogy a legjobb IT-megoldásokat kiötlő résztvevőket összekössék olyan szervezetekkel vagy lehetőségekkel, amelyek segíteni tudják a koronavírus elleni harcot.
A versenyen 175 országból több mint 18 ezren vettek részt, és összesen 1561 projektet hoztak össze hét tág témakörben: egészségügy, egészségügyi oktatás, veszélyeztetett populációk, vállalkozások, közösség, oktatás és szórakozás. Egy több mint 350 fős zsűri válogatta ki a legjobbnak ítélt 89 projektet – a zsűrizésben mások mellett olyan cégek képviselői is közreműködtek, mint az Egészségügyi Világszervezet (WHO), a Facebook, a Google, a Microsoft, az Amazon, az Intel vagy a Pfizer.
A 89 legjobb projekt között egy magyar páros munkája is helyet kapott: az egyaránt jogászként végzett, de mesterségesintelligencia-fejlesztéssel is foglalkozó Ország-Krisz Axel és Vécsey Richárd Ádám egy olyan terméket (Deep Model Core Framework, vagy DoF) hozott létre, amely a leírás szerint „a mesterséges intelligencia tanításának határait tolja ki, informatikai és jogi értelemben egyaránt.”

A termék az alkotók szerint „világszerte megkönnyíti a fejlesztők munkáját, hiszen segítségével a tanító adatbázisok mérete csökkenthető, és a mesterséges intelligenciák betanításához szükséges idő is rövidebb. Az informatikai előnyökön túlmenően az általunk fejlesztett keretrendszerben tárolt adatok világszintű cseréje sem ütközik jogi akadályokba, a szenzitív és személyes adatok tárolása és kezelése nemcsak GDPR kompatibilis módon történik, de megfelel például a hazai egészségügyi adatok kezelésére vonatkozó előírásoknak is.”
A DoF keretrendszer a neurális hálózat kimeneti számértékeit kezeli, ami azért fontos, mert jelentős gyorsulás érhető el a mesterséges intelligencia betanítási folyamata során, ha a neurális hálót „félbevágják”, és az előre betanított modellt és annak kimenetét külön kezelik.
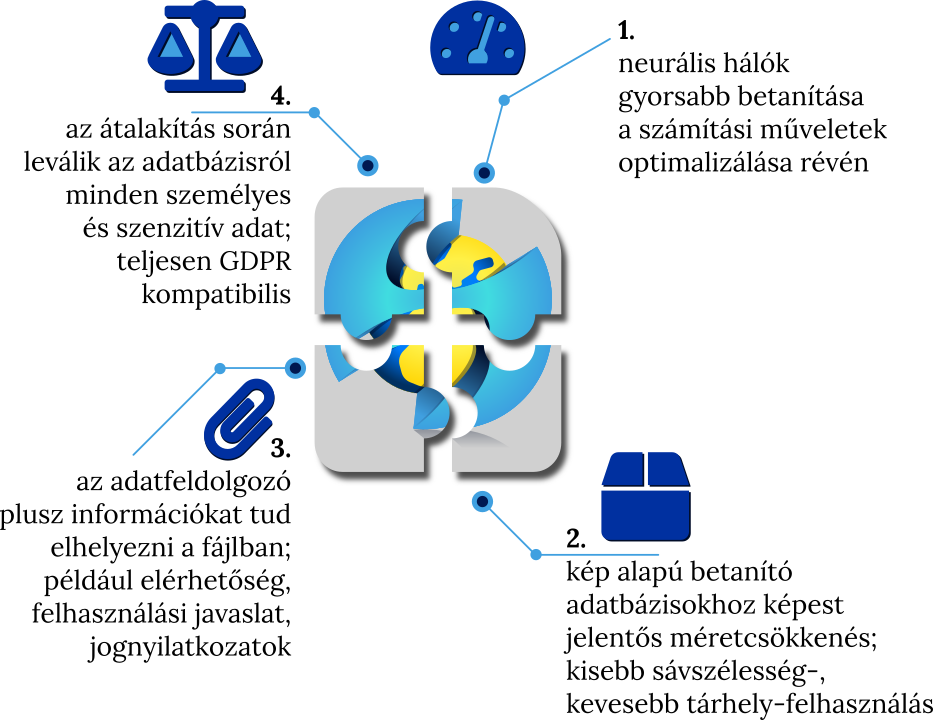
„Az előre feldolgozott adatokat speciális fájlformátumban tároljuk el, amely jelentős méretcsökkenést eredményez. A betanítást alapesetben képek segítségével végzik, de a képeknél lényegesen kisebb helyen tárolható el az adat akkor, ha csupán a szükséges matematikai összefüggések kerülnek kimentésre. A kutató, aki ezt a kimentést és letárolást elvégzi, hozzáadhat különböző megjegyzéseket, amelyek segítik a mesterséges intelligencia fejlesztő munkáját. Ilyen kommentár lehet az eredeti adatokon végzett módosítások leírása, a javasolt felhasználás módja, kapcsolattartási információk, vagy az eredeti adatok elérhetősége, hogy a folyamat bármikor visszaellenőrizhető, transzparens legyen” – írják a magyar versenyzők.
Ezzel lehetővé válik a nagyméretű betanító adatok nemzetközi cseréje, hiszen nem kell orvosi adatok tekintetében engedélyeket kérni, mivel a tényleges, orvosilag releváns adat a tárolt változatban már nincs jelen, és nem is fejthető vissza. Ez a mostani járványhoz hasonló időszakokban különösen fontos, mert nem kell hatósági döntésekre várni az adattovábbításhoz, hosszabb távon pedig azért van jelentősége, mert az új módszer segítségével úgy végezhetnek mesterséges intelligenciára támaszkodó fejlesztéseket az Európai Unióban, hogy a felhasznált adatok hosszas jogi procedúra és engedélyezési eljárások nélkül megfelelnek az uniós adatvédelmi rendeletnek, a GDPR-nak is.
A koronavírus-járvánnyal kapcsolatos tudományos eredmények bemutatását a Dataizmus Zrt. támogatta.
Kapcsolódó cikkek a Qubiten:

Így áll a techbiznisz a járványkorszak hajnalán
Hogyan vizsgáznak a globális járvány idején a kriptopénzek és a hakniszektor? Mit érzünk az internet iránt most, hogy azért omlik össze minden, mert kedvenc sorozatunkat nézzük? Vagy nem is omlik össze minden? Drótos/fótos trendriport a tech világából.

Komoly problémát okoz, hogy az amerikai munkanélkülieket egy ősi programozási nyelven tartják nyilván
A munkából kiesők adatainak kezelését végző COBOL-hoz alig értenek már az USA-ban, a heti 600 dolláros extra juttatás sem a munkanélküli-nyilvántartás adminisztrációján keresztül érkezik az érintettekhez.

Harcolj a vírus ellen, adj adatot!
Az okostelefonod tudja, merre jársz, sőt némelyik készülék már azt is képes jelezni, ha hőemelkedésed van. Egy német kutató szerint annál jobban nyomon lehet követni a vírus terjedését, minél többen ajánlják fel tudományos célokra az adataikat. Sokan a totális megfigyelés miatt nem lennének erre hajlandók.