Forradalmi áttörés: a mesterséges intelligencia a DNS-ből megmondja, hogyan fognak kifejeződni a gének

A mesterséges intelligencia hamarosan a genetika orákulumává válhat, és a DNS bázissorrendje alapján megjósolhatja, mennyire erősen fejeződnek majd ki a gének, amelyek az élőlények szinte összes életfolyamatára kihatnak. Egy a Nature-ben közölt kutatás szerint ez forradalmi előrelépést jelenthet a biológiában, legalábbis ha a következő években sikerül a módszert többsejtű élőlényekre is kiterjeszteni.
Bár az élőlények genetikai szabályozásának működésébe és evolúciójába most először tudtak betekintést nyújtani, a mélytanulási (deep learning) algoritmusok nem először hoznak áttörést az élettudományokban. Mint arról februárban írtunk, a DeepMind által kifejlesztett AlphaFold2 algoritmus 2020-ban sosem látott pontosságot ért el fehérjék háromdimenziós szerkezetének meghatározásában, és ezzel majdnem felzárkózott a költséges és hosszadalmas kísérleti módszerek precizitásához. Ahogy az AlphaFold2-nek, az új genetikai orákulumnak is fontos gyakorlati alkalmazásai lesznek a biotechnológia és a szintetikus biológia területén.
Az Eeshit Dhaval Vaishnav (MIT) és Carl de Boer (Brit Columbia-i Egyetem) által vezetett kutatócsoport egysejtű élesztőgombákkal (Saccharomyces cerevisiae) végzett kísérletek adataival tanította a mély neurális hálózatokat alkalmazó algoritmusokat, majd azok előrejelzéseit újabb kísérletekkel igazolták. A kutatók elsősorban azt szerették volna megérteni, hogy a génszabályozásáért felelős DNS-szakaszok mutációkkal való megváltozása milyen következményekkel jár, és ez mit árul el a genetikai szabályozás evolúciójának alapelveiről.

Az emberi genom mindössze 0,9 százaléka kódol közvetlenül fehérjéket, és kevesebb mint 10 százalékának van (vagy lehet) valamilyen funkciója. Ezen szakaszok egy része a gének kifejeződésének szabályozásáért felel, vagyis azt befolyásolja, hogy azokból mikor mennyi RNS íródik át, ami fehérjét kódoló gén esetén a sejt riboszómáin később lefordítódhat fehérjékké is. A DNS-szabályozó szekvenciáiban bekövetkező mutációk befolyásolni tudják a gének kifejeződésének mértékét, idejét, helyét, és ezzel kihatnak az élőlény megfigyelhető adottságaira (fenotípus), illetve fitneszére, vagyis az egyed szaporodási sikerére. Különösen fontosak a génszabályozásban a cisz-regulátor elemek, melyek valószínűleg a biológiai változatosság jelentős részéért felelnek. Közéjük tartoznak a kutatók mélytanulási algoritmusa által vizsgált promoter szekvenciák is, melyek a hozzájuk kapcsolódó fehérjék segítségével elindítják a DNS-ről RNS-re való átírást egy adott szakaszon. A kutatók szerint annak megértése, hogy miként befolyásolja a promoterek változása a génkifejeződést, a fenotípust és a fitneszt, kulcsfontosságú a genetikai szabályozás evolúciójának megértéséhez.
A Nature-ben az eredményeket kommentáló Andreas Wagner, a Zürichi Egyetem evolúcióbiológiai tanszékének kutatója szerint a tanulmányban meggyőzően igazolták kísérletileg a neurális hálózati algoritmus előrejelzéseit, amik azt mutatják, hogy egy igen hatékony orákulumot hoztak létre a génkifejeződés mértékének megjóslására. Wagner úgy véli, hogy – a limitációi ellenére – a kutatás segíthet a génszabályozás evolúciójának megértésében, és kívánt kifejeződési szinttel rendelkező gének mérnöki tervezésében. Optimista arra nézve is, hogy a megközelítés az élesztőgombáknál bonyolultabb genetikai szabályozással rendelkező élőlényekben is működhet.
Újabb áttörést hoztak a mélytanulási algoritmusok
A kutatók az algoritmusokkal a promoterek 80 bázispárból álló DNS-szekvenciáit tanulmányozták, miután jelentős kísérleti erőforrások bevetésével megtanították nekik, hogy adott szekvenciák milyen mértékű génkifejeződéshez párosulnak. Ehhez az élesztőgombák sejttenyészeteibe sárga fluoreszcens fehérjét (YFP) kódoló gént vittek be, egy annak kifejeződésére ható promoterrel együtt. Összesen 18, két különböző táptalajt használó sejtkultúrát vizsgáltak, a fluoreszcens fehérje mennyiségét, így a génkifejeződés intenzitását mérő Sort-seq módszer, illetve az egyes sejtkultúrákra jellemző promoterek bázissorrendjének felderítése, vagyis megszekvenálása segítségével. A kutatásban alkalmazott, általában vizuális információk vizsgálatára használt konvolúciós neurális hálózati modellek tanításához több mint 30 millió szekvenciát mértek meg az egyik táptalajon, és 20 milliót a másikon.
A tanulási folyamat után letesztelték, hogy képes-e a neurális háló általánosítani ismeretlen szekvenciákra is. Ehhez az algoritmus új promoterek által eredményezett génkifejeződésre tett jóslatokat, majd ezeket a kutatók összehasonlították a promoterek kísérletileg mért hatásával, kiváló teljesítménnyel. A későbbi tesztjeik is ezt igazolták – az általuk bevetett algoritmusok korábbi biokémiai modellekhez képest 45 százalékkal kevesebb hibát produkáltak. Érdekes részlet, hogy amikor más, meglévő genetikai modelleket tanítottak a több millió mérésből álló adatsorukon, szintén kiváló eredményt értek el, ami véleményük szerint bizonyítja a neurális hálózati algoritmusok jó előrejelző képességét.
A Sewall Wright által 90 évvel ezelőtt a genotípus (az élőlény genetikai információjának összessége) és a szaporodási siker közötti összefüggés megértésre kidolgozott matematikai módszert, a fitnesztájképek (fitness landscapes) készítését is elővették a kutatók. Az algoritmus segítségével megjósolták a promoter szekvenciák és az élőlény fitnesze közti kapcsolatot, majd ezt 2 dimenziós grafikonokon ábrázolták. Bár korábban is voltak kísérleti próbálkozások a promoterek génkifejeződésére mért hatásának ezzel történő vizsgálatára, a kutatók szerint ezek az általuk létrehozottaknál korlátoltabbak voltak.
„Végre van egy orákulum, amitől megkérdezhetjük, mi van, ha az összes lehetséges mutációt kipróbálnánk ezen a szekvencián, vagy milyen új szekvenciákat tudunk tervezni, hogy elérjük a kívánt génkifejeződést” - mondta Aviv Regev, a tanulmány egyik szerzője. Regev szerint innentől más kutatók is fel tudják használni ezt az algoritmust a saját evolúciós kérdéseik megválaszolására, valamint a mögöttes biológiai folyamatok jobb megértésére. Mint elmondta, ez a megközelítés számos probléma megoldását segítheti, például az emberi megbetegedésekkel összefüggő szabályozó régiók genetikai variánsainak feltárását.
A kutatók az algoritmusokat elsőként szintetikus biológiai célra vetették be, és a génkifejeződés mérnöki szabályozásában tesztelték hatékonyságukat. 500 darab olyan szekvenciát terveztettek velük, amelyek extrém magas vagy extrém alacsony génkifejeződést produkálnak, legalábbis az előrejelzés szerint. A kísérleti tesztekből kiderült, hogy ez a várakozásokon felül sikerült, mert a mesterségesen előállított szekvenciák 99 százalékkal extrémebb génkifejeződéshez vezettek, míg 20 százalékuk olyan értékeket ért el, amely bármilyen normál szekvenciáét meghaladta.
Ahhoz, hogy komplex evolúciós kérdéseket is vizsgálni tudjanak reálisan elérhető számítási kapacitás mellett, olyan, úgynevezett transformer gépi tanulási modelleket dolgoztak ki, melyek kevesebb paraméterrel rendelkeznek, kompatibilisek a kutatók által használt speciális, az AI-számításokat gyorsító integrált áramkörökkel, valamint teljesítményük a fő neurális hálózati algoritmusaikhoz mérhető a génkifejeződés előrejelzésében.
Mit mond a mesterséges intelligencia a génkifejeződés szabályozásának evolúciójáról?
A mélytanulási algoritmus olyan evolúciós kérdésekre is választ adott, mint hogy mennyire gyorsan képes a természetes szelekció optimális mértékű génkifejeződést kialakítani, hogy mik a szabályozó szekvenciákra nehezedő szelekciós nyomás jelei, és hogy hogyan alakítja ez a promoterek mutációkkal szembeni ellenállóképességét.
Amikor a kutatók a neutrális evolúciós folyamatokhoz tartozó genetikai sodródás hatását vizsgálták, meglepő dolgot találtak. Ahogy nőtt a mutációk száma a szabályozó szekvenciákban, úgy tért el egyre inkább a génkifejeződés mértéke is az eredetitől, 32 mutációnál pedig már nem is emlékeztettek egymásra a hatásukat tekintve. Az algoritmus szimulációit kísérleti eredmények is igazolták. Korábbi elképzelésekhez képest arra is fény derült, hogy az evolúció nem feltétlenül a bonyolultabb szabályozási megoldásokat részesíti előnyben. Ahogy egyre több mutáció jelent meg a szekvenciákban, a promoterekhez kötő és azokra ható, transzkripciós faktor nevű fehérjék szerepében lassú változások álltak be. A génkifejeződés aktuális értékének fenntartását favorizáló stabilizáló szelekció (a természetes szelekció egyik altípusa) ezzel a szabályozó rendszer bonyolultságának mérsékléséhez vezetett.
A kutatók megvizsgálták azt is, mi történik olyan körülmények közt, ahol viszonylag alacsony a mutációk száma, de hatásuk egyértelműen csak hasznos, vagy káros lehet (és neutrális nem). A változatos génkifejeződéssel kezdő promoterek evolúciója magas vagy alacsony irányba indult, és már három-négy mutációval extrém szinteket ért el, amit az algoritmus előrejelzéseit tesztelő kísérletek is igazoltak. Természetes szabályozókkal végzett kísérletek is arra utaltak, hogy a mutációk hatásai a hatványtörvényt követik, azaz már néhány változásnak is jelentős hatása van a gének kifejeződésére.
Ez Vaishnav, Boer és munkatársaik szerint azt mutatja, hogy ezeknek a szabályozó elemeknek elég gyors az evolúciójuk, legalábbis ha nem kell egyszerre egymásnak ellentmondó célokat elérniük. A kísérletben az URA3 gén megmutatta, hogy magas kifejeződése táptalajtól függően előnyös vagy hátrányos az élesztőgomba fitneszére, és hogy nehezebb egyszerre különböző körülményekhez alkalmazkodnia a génkifejeződésnek, mint egy adott helyzetben optimális állapotot eltalálni. A kutatók úgy látják, hogy a például állatokban megfigyelhető komplexebb genetikai szabályozáshoz több, egy adott génre jutó szabályozó szekvenciára, például enhanszerekre, és több transzkripciós faktorra van szükség.
Kiderült az is, hogy a szabályozó szekvenciákra nehezedő szelekciós nyomás erős korlátokat szabhat funkciójuknak, ez viszont ellenállóbbá is teheti őket jövőbeli mutációkkal szemben. Bár arról a szakemberek nincsenek meggyőződve, hogy az evolúció direkt erre szelektálna, mert ez önmagában nem jelent akkora előnyt az élőlénynek. Így szerintük ez inkább a szabályozók evolúciós fontosságát és evolúciós történetének hatását mutatja.
„A szabályozás evolúcióját és a fitnesztájképeket évtizedek óta tanulmányozzák. Úgy gondolom, hogy a mi keretrendszerünk sokat fog segíteni alapvető, máig nyitott kérdések megválaszolásában, a szabályozó DNS evolúciójának és evolúciós képességének megértésében, valamint új alkalmazásokra használható biológiai szekvenciák tervezésében” - nyilatkozta Vaishnav, a tanulmány egyik vezető szerzője.
A kutatók tehát egy olyan mélytanulási rendszert hoztak létre, amely több millió mérésen edződve képes pontosan előre jelezni, mi lesz a gyakorlati hatása egy gén átíródására egy adott szabályozó szekvenciának. Azt remélik, hogy módszerük jelentős előrelépésekhez vezethet a szintetikus biológiában, a sejt- és génterápiában, valamint az evolúció vizsgálatában. Ahhoz viszont, hogy ezek az algoritmusok tényleg forradalmat hozzanak, túl kell lépniük szabályozó régióra vagy fajra vonatkozó specifikusságukon, és meg kell tanulniuk a többsejtűek sokkal bonyolultabb genetikai viszonyai között is boldogulni.
Kapcsolódó cikkek a Qubiten:
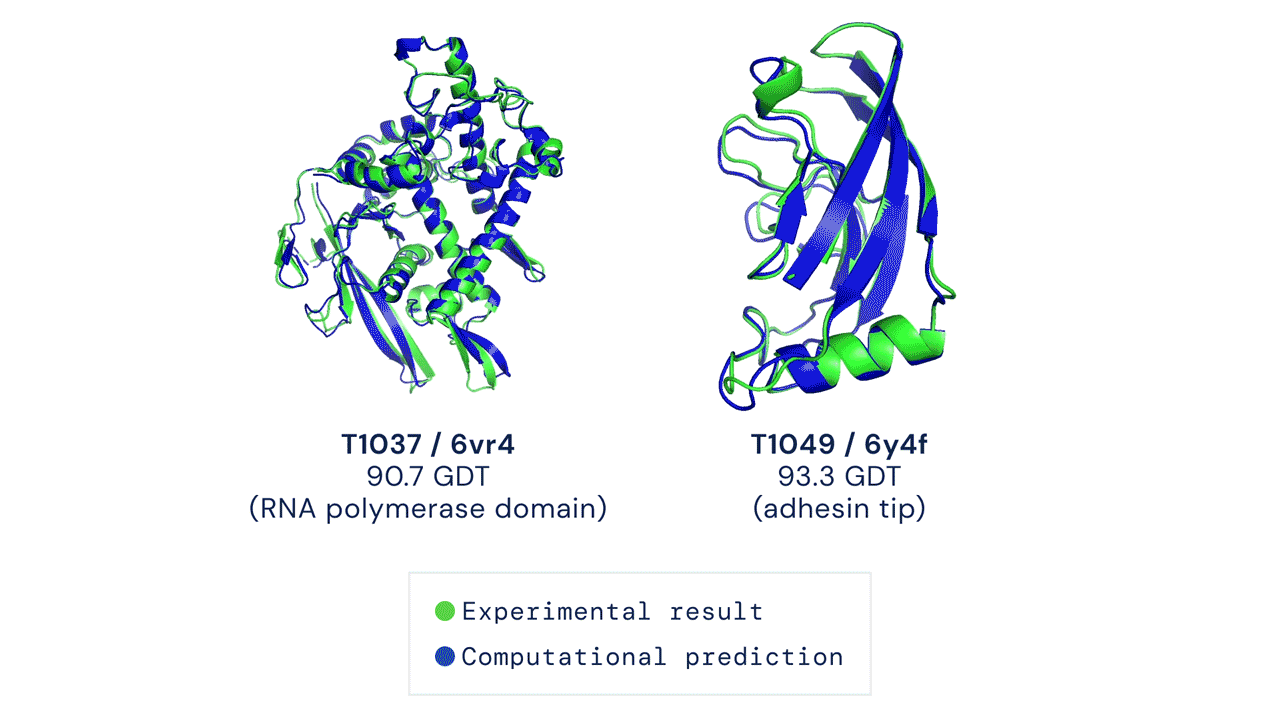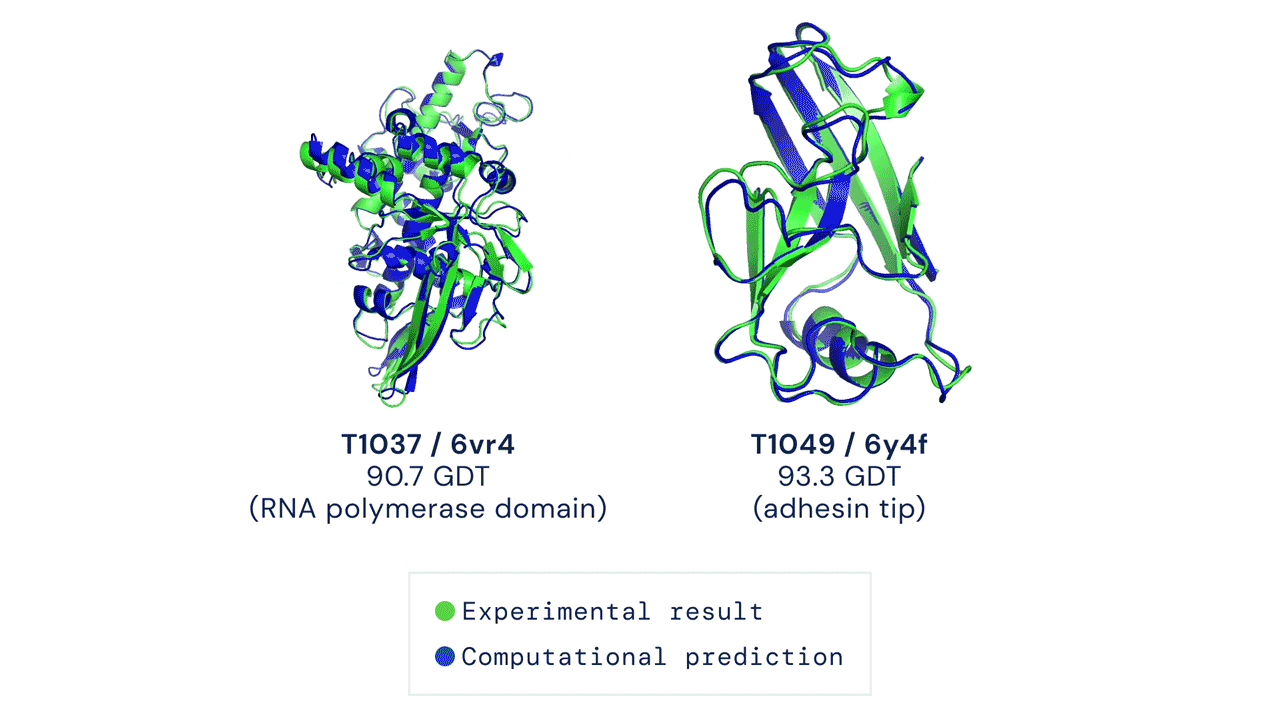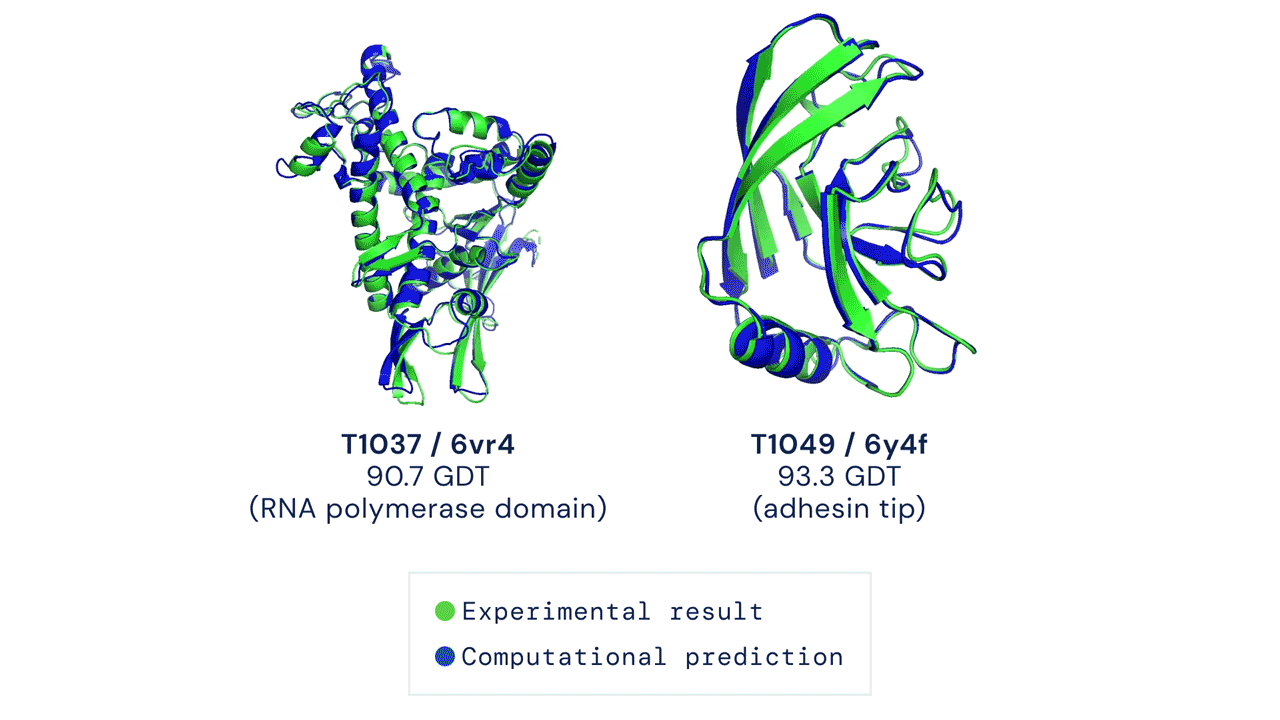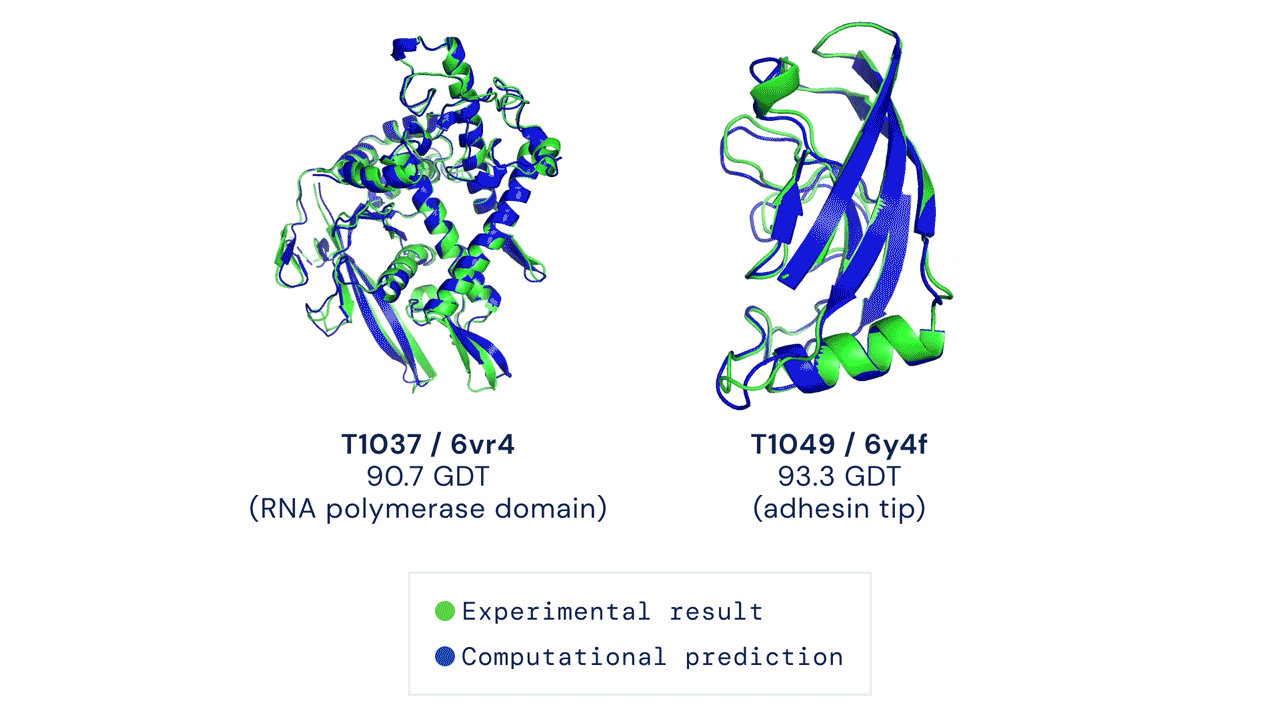
Áttörést hoz a biológiába a minden eddiginél pontosabb fehérjekutató algoritmus, az AlphaFold2
A Google-féle DeepMind legújabb AI-modellje az aminosavak sorrendjéből egész pontosan megfejti a fehérjék háromdimenziós térszerkezetét. A mesterséges intelligencia forradalmasíthatja a gyógyszerkutatást: van olyan rákkutató cég, ahol az AlphaFold2 a korábbi egy hónapról néhány órára csökkentette a hatóanyag-jelölt fehérjék megtalálását.

Íme a GT Sophy, a mesterséges intelligencia, amely a legjobb esportolókat is legyőzte a virtuális autóversenypályán
A Sony AI autóversenyző algoritmusa néhány nap alatt jobb köridőket ért el a Gran Turismóban, mint az emberi játékosok, majd egy versenyen legyőzte a világ legjobb GT-játékosaiból álló négyfős csapatot. A fejlesztés nemcsak realisztikusabb játékok létrehozásában, de a robotika, a drónok vagy az önvezető járművek területén is hasznos lehet.

A DeepMind mesterséges intelligenciája már egy középiskolás szintjén teljesít szövegértésben
Állampolgári ismeretekből 83,9, pszichológiából 81,8 százalékos eredményt ért el az eddigi leghatékonyabb nyelvi AI-modell, a Gopher a középiskolai teszteken. Matekból és fizikából kell még javítani.

Tíz éven belül jön a mesterséges matematikus, amit a Google magyar kutatója fejleszt
Christian Szegedy, a Google Research magyar kutatója csapatával olyan rendszert épít, ami nemsokára túlszárnyalhatja a matematikusok legvadabb álmait: rutinból ellenőrzi majd azokat a bizonyításokat, amelyeket csak néhány ember képes megérteni a Földön, új sejtéseket jósol meg, és olyan távlatokat nyit a matematikában, amelyekről ma még fogalmunk sincs. A fő cél egy programozási rendszer, amelynek interakcióit nem lehet megkülönböztetni az emberitől.