Agyi jelekből, meglepő pontossággal olvastak emberek gondolataiban egy amerikai kísérletben

A Texasi Egyetem kutatói olyan agyi dekódert fejlesztettek ki, amely noninvazív módon képes az agyi aktivitást valós idejű szövegfolyamra fordítani. A módszerrel meglepő pontossággal tudták rekonstruálni a beszédet a funkcionális MRI-vizsgálatból származó adatok alapján, miközben a kísérlet résztvevői valamilyen történetet hallgattak vagy elképzeltek magukban.
A tavaly ősszel már belengetett, de a Nature Neuroscience szaklapban most, május 1-én megjelent kutatásban leírt eljárás nagy előnye a korábbi nyelvi dekódoló rendszerekhez képest, hogy az már nem igényli implantátumok behelyezését és sebészeti megoldásokat, így új módszereket helyez kilátásba a beszéd helyreállítására olyan betegeknél, akiknek például sztrók vagy motoros neuronbetegség miatt akadnak nehézségeik a kommunikálással.
Bár az fMRI-vizsgálatok rendkívül nagy felbontással képesek leképezni egy adott agyi terület aktivitását, a technológiával együtt jár egy olyan mértékű késleltetés, ami ellehetetleníti az aktivitás valós idejű követését. Az fMRI ugyanis az agyi aktivitásra adott véráramlási választ méri, ami körülbelül 10 másodperc alatt zajlik le, miközben a természetes beszédre mutatott agyi válasz során mindössze néhány másodperc alatt terül szét az adott információhalmaz.
Ezt az akadályt a nagy nyelvi modellek felhasználásával sikerült kiküszöbölni. Ezek ugyanis képesek számokban reprezentálni a beszéd szemantikai jelentését, és így a kutatók meg tudták vizsgálni, hogy az idegi aktivitás mely mintázatai felelnek meg egy adott jelentésű szókapcsolatnak. A kísérletben a ChatGPT alapját is képző nyelvi modell egy korai változatát, a GPT-1-et tanították be a Redditről származó szövegeken, illetve a Moth Radio Hour és a New York Times-féle Modern Love podcastek adásain és leiratain.
A kísérlet három résztvevőjének egyenként 16 órát kellett feküdnie egy fMRI-szkennerben, miközben a GPT-1 által betanult podcasteket és a modell előtt ismeretlen adásokat hallgattak. A modell megtanulta megjósolni, hogy bizonyos szavak milyen agyi aktivitást váltanak ki, majd amikor új epizódokon tesztelték, a modell vissza tudta nyerni a résztvevők agyi aktivitásából a hallottak lényegét, gyakran akár pontos szavakat és mondatokat is azonosítva.
Igaz, a nyelv bizonyos aspektusaival valamiért nehezen boldogult, például a személyes névmásokat rendre keverte. „A rendszerünk a gondolatok, a szemantika és a jelentés szintjén működik. Ez az oka annak, hogy nem a pontos szavakat kapjuk meg, hanem azok lényegét” – mondta a kutatást vezető Alexander Huth a Guardiannek. Amikor például egy résztvevőnek a „Még nincs meg a jogosítványom” szavakat játszották le, a dekóder azt olvasta ki, hogy „Még el sem kezdett tanulni vezetni”, nőnemű (she) névmással. Míg azt, hogy „Nem tudtam, hogy sikítsak, sírjak, vagy elfussak. Ehelyett azt mondtam: Hagyj békén!”, így fordította: „Elkezdtem sikítani és sírni, aztán csak annyit mondott: Mondtam, hogy hagyj békén!”
A pontatlanságok ellenére a kutatók lenyűgözőnek találták az eredményt, Huth szerint „egy nem invazív módszer esetében ez igazi ugrás az eddigiekhez képest, ami jellemzően egy-egy szót vagy rövid mondatot jelentett”. Ráadásul a módszer akkor is működött, amikor a résztvevőknek néma rövidfilmeket kellett megnézniük, miközben a szkennerben feküdtek: a dekóder pusztán az agyi aktivitásuk alapján képes volt viszonylag pontosan leírni a filmek tartalmának egy részét.
A tanulmány társszerzője, Jerry Tang az MIT Technology Review-nak elmondta, hogy a kutatók nagyon komolyan veszik azokat az aggodalmakat, miszerint a hasonló rendszereket rosszindulatúan is fel lehet majd használni, és igyekeznek mindent megtenni ennek elkerülése érdekében. A kísérletben használt rendszer mindenesetre személyre szabott volt, és csak az alanyok saját agyi aktivitásán betanított dekódermodellekkel működött. Amikor megpróbálták egy másik személy adatain betanított modell segítségével dekódolni az egyes résztvevők beszédérzékelését, „alig több mint véletlenszerű” eredményeket kaptak.
Kapcsolódó cikkek a Qubiten:
Pusztán az emberek agyi jelei alapján kitalálja egy algoritmus, miről szól a film, amit megnéztek
Ez az első alkalom, hogy amerikai tudósoknak noninvazív módszerrel, funkcionális mágneses rezonanciavizsgálattal (fMRI) sikerült rekonstruálni emberi gondolatok tartalmát.
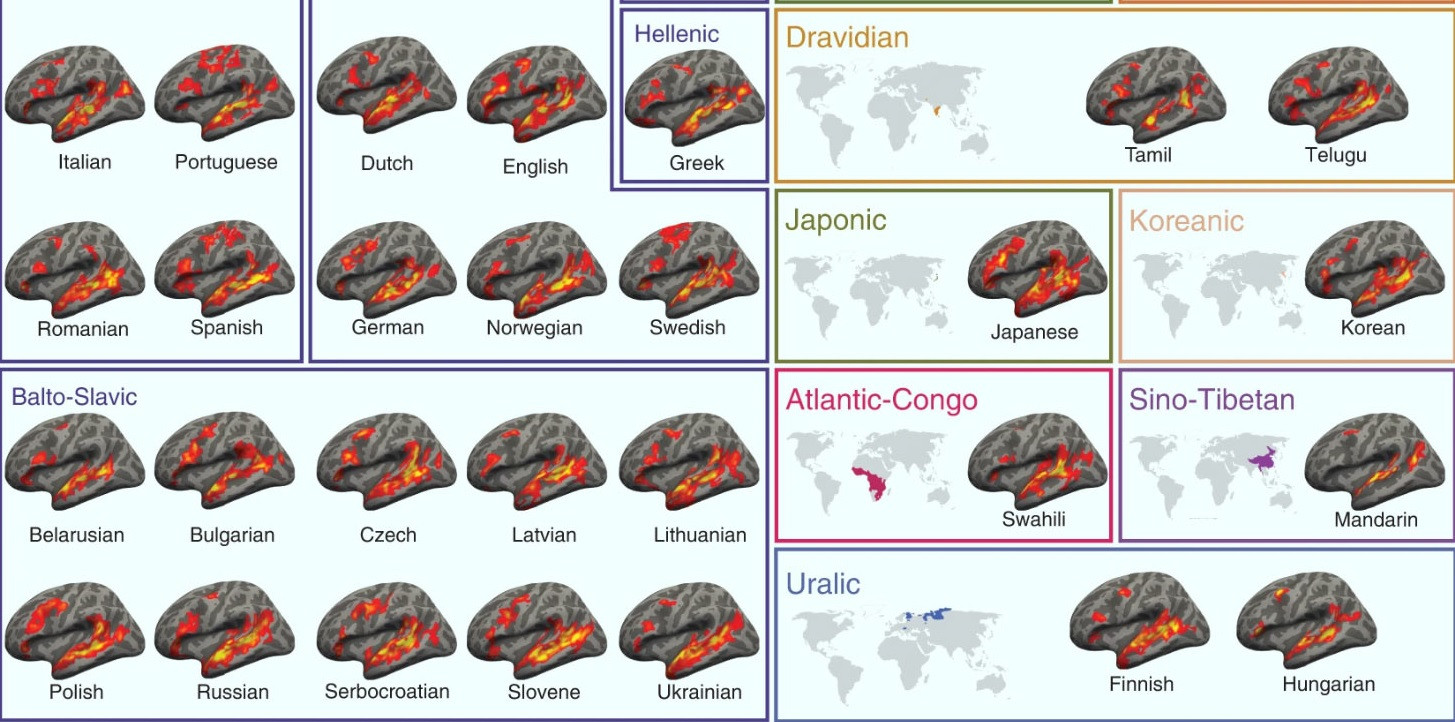
Univerzálisnak tűnik a nyelvfeldolgozás agyi hálózata
A Massachussets Institute of Technology kutatói fMRI-felvételek alapján azt állítják, hogy ugyanazok az agyterületek aktiválódnak függetlenül attól, hogy mi az illető anyanyelve.