A ChatGPT csökkenti a nyelvi sokszínűséget, és ezzel rengeteg kárt okozhat

Írnál egy jó motivációs levelet, álláshirdetésre jelentkeznél vagy hivatalos választ kellene küldeni egy ügyintézés miatt? Ezekre a feladatokra, és persze még sok másra is, kiválóan alkalmasak az olyan szöveggenerátorok, mint az OpenAI-féle ChatGPT vagy a Google chatbotja, a Gemini. Olyannyira, hogy a legfrissebb statisztikák szerint az előbbit hetente mintegy 400 millióan használják világszerte, annak ellenére, hogy kínai riválisa, a DeepSeek is elkezdte rohamtempóban magához csábítani a felhasználókat. Az összes generatív AI-eszközt eddig közel hárommilliárdszor próbálták ki.
Ilyen adatok mellett nem csoda, hogy a Dél-kaliforniai Egyetem kutatói úgy kezdik a 2025 februárjában a preprinteket, vagyis tudományos bírálaton (peer-review) nem átesett tanulmányokat gyűjtő ArXiv portálon megjelent kutatásukat, hogy a ChatGPT, a Gemini és más csetbotok képében elérhető nagy nyelvi modellek veszélyeztetik a nyelvi sokféleséget. „Uniformizálják a nyelvet, csökkentik a nyelvi sokféleséget és megváltoztatják, ahogy a szövegeken keresztül megjelenítődnek a személyes tulajdonságok. Ezeknek a változásoknak az identitásra, a kultúrára és a méltányosságra is mélyreható következményeik vannak” - írta Linkedin-oldalán Zhivar Sourati, a Dél-Kaliforniai Egyetem doktori hallgatója, a tanulmány első szerzője.
A gyakoriság csapdájában
A nagy nyelvi modelleket úgy tréningelik, hogy a statisztikailag legvalószínűbb folytatását adják bármilyen szövegnek, ez a folyamat viszont a domináns nyelvhasználatnak és nyelvi mintázatoknak kedvez. Bár a promptolással lehet csiszolni a válaszokon, például úgy, hogy megadjuk, milyen nyelvi regiszterben szólaljon meg a ChatGPT, a kutatók szerint ez a rendszerben meglévő alapvető korlátokat nem igazítja ki. Sőt, a nyelvhasználat homogenizációjának kockázatát hordozza, ami szerintük már javában zajlik.
Ennek vizsgálatához négy kutatást végeztek el. Az elsőben arra voltak kíváncsiak, hogyan változott meg különféle platformokon az írások stílusa a nagy nyelvi modellek berobbanása óta, a másodikban azt mutatták ki, hogy amikor a ChatGPT-t és társait az emberek által írt szövegek feljavítására használják, az mennyire csökkenti a nyelvi sokféleséget, miközben a szöveg jelentése ugyanaz marad. A harmadikban azt vizsgálták meg, hogy az írott szövegből mennyivel nehezebben lehet a személyiségjegyekre következtetni, ha az adott írást nagy nyelvi modellel írják át, a negyedik kutatás pedig arra világít rá, hogy a nagy nyelvi modellek nagy mértékben erodálják a nyelvi mintázatok és a személyes tulajdonságok közötti kapcsolatot, és hogy ez megváltoztathatja a nyelv és az identitás közötti viszonyt.
Gépiesedő posztok, hírek, kutatások
A kutatás első részében Sourati és társai három különböző adatforrást választottak ki a szövegek gyűjtésére. Először is a Reddit egyik aloldalán (r/WritingPrompts) gyűjtötték a hozzászólásokat. Több mint 310 ezer, 2018 január és 2024 novembere között keletkezett történetet szedtek össze, amelyek nyelvi és stilisztikai megkötések nélkül tartalmazták a felhasználók saját kreatív történeteit.
A másik forrásuk a Patch News amerikai híroldal-aggregátor volt, ami az ötven amerikai állam 488 megyéjének szolgáltat helyi híreket, és ahová csaknem 20 ezer szerző küld be folyamatosan írásokat. Ezek a cikkek a nagy híroldalakhoz képest stilisztikailag kevésbé behatároltak, így jobban megmutatkozhat az egyéni hangok közötti különbség. A kutatók erről a platformról 2018 január és 2023 novembere között majdnem 380 ezer cikket gyűjtöttek össze. Harmadik forrásuk az ArXiv online adatbázis volt, ahol kutatók osztják meg tudományos ellenőrzésen, vagyis peer review-n még nem átesett tanulmányaikat. Összesen több mint 80 ezer tanulmány absztraktját vizsgálták meg 2018 január és 2024 novembere között.
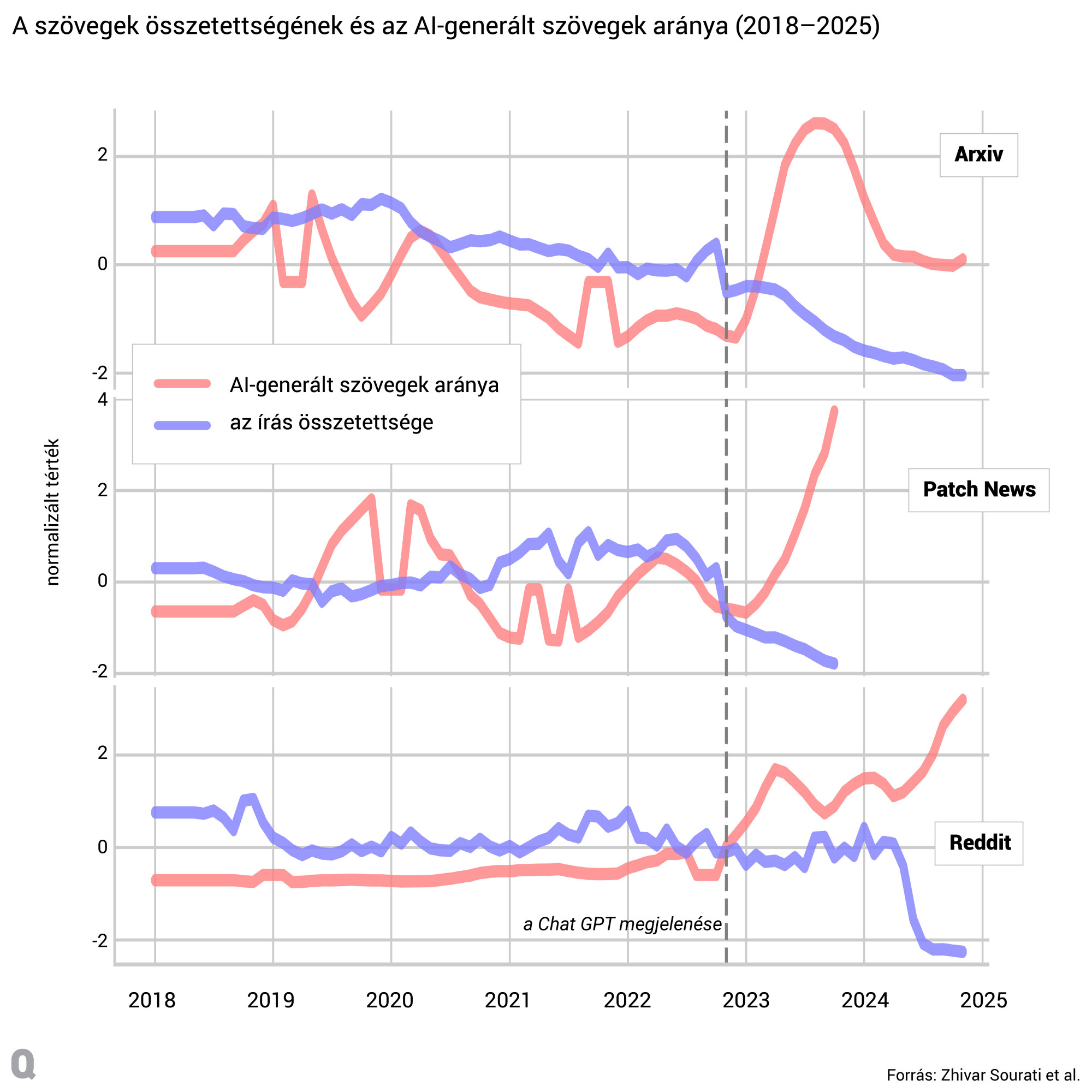
A kutatás első része arra mutat rá, hogy ezeken az oldalakon a ChatGPT megjelenése óta vészesen csökken a nyelvi sokszínűség, elkezdett szűkülni és uniformizálódni az írások kifejezésmódja.
Miért baj, ha csökken a nyelvi diverzitás?
A nyelvi variabilitás rengeteg plusz információt hordoz az egyénekről és a közösségekről egyaránt. Az, hogy ki milyen kifejezéseket, szavakat, mondatszerkezeteket használ, utalhat a földrajzi tájegységre, ahonnan az illető származik, a társadalmi státuszára, az iskolázottsági szintjére, azokra a kisebb-nagyobb társadalmi, kulturális, generációs csoportokra, amelynek tagja. Ha a nagy nyelvi modellek elkezdik az írást egységesíteni, sokkal nehezebben lehet kimutatni az ilyen személyiségjegyeket.
Ez pedig a kutatók szerint számos területen hátrányos lehet. Az elmúlt években például számos kutatócsoport épített fel olyan depressziófelismerő eszközöket, amelyek hang, szöveg vagy arckifejezések finom árnyalatai alapján igyekeznek diagnosztizálni a depressziót, többek között nyilvános közösségi média posztok és más szövegek alapján. Ezeknek a hatékonysága kérdésessé válhat, ha a jövőben még gyakoribbá válik a nagy nyelvi modellek használata. Egy másik példa a szövegelemzésen alapuló marketingtevékenység, amely során előszeretettel használnak mesterséges intelligenciát a hirdetések személyre szabására és targetálására. Ezeket szintén okafogyottá teheti a generatív AI, hiszen ha homogenizálódnak a szövegek, akkor azokat nem nagyon lehet személyre szabni.
Ezek viszont csak elszórt és kevéssé jelentős példák ahhoz képest, hogy a nyelvhasználat homogenizációja mennyire negatív hatással lehet a jövőben a nyelvi örökség, a kulturális gazdagság megőrzésére. Ezek azért fontosak, mert az emberi faj túléléséhez nélkülözhetetlen gondolkodásbeli sokféleség kulcsát jelentik.
Kapcsolódó cikkek a Qubiten:
Kiderült, melyik chatbotokat és más generatív AI-eszközöket használják a legtöbben, a Prezi is rajta van a listán
A Világbank kutatása szerint rá vagyunk csavarodva a szöveggenerátorokra, de a kép- és videókészítő platformoknál már nem fut annyira a szekér.

Húsz terület, ahol a ChatGPT már most megkönnyíti az életedet
Ha a Google a barátunk, akkor minek nevezzük az AI-chatbotokat, amik egyszerű válaszok helyett már részletes magyarázatokat adnak, és még vissza is kérdezhetünk? Tippek és trükkök a főzéstől a nyelvtanuláson át a lelki segélyig.