Miért terjednek hétszer gyorsabban az álhírek, mint a valódiak?

12 fejezet, 238 oldal, soronként átlagosan 7 szóval számolva összesen 51 646 szó. Ezzel kezdődik az adatosítás, jelen esetben Janosov Milán adattudós és hálózatkutató, a Qubit állandó szerzője első könyvének, a DATA - Így hálóznak be az adataid című művének leírása számokban.
Ha az ember ért az adatvizualizációhoz és az adattudományhoz, miután a körülötte lévő világból kibányászta és letisztította a számára érdekes adathalmazt, feltárja, hogy ezek az adatok hogyan rendeződnek hálózatba, és ábrázolja a számszerűsített információcsomagot. Grafikonon mutathatja be, melyik fejezetben hogyan oszlik el az információ, szófelhőbe rendezheti a kulcsszavakat, megállapíthatja, hogyan rendeződnek hálózatba, és ha még egy algoritmust is ráenged az adathalmazra, a rejtett mintázatok kirajzolása után talán azt is megtudhatja, mekkora valószínűséggel hogyan folytatódhatna a könyv.
Maga a DATA épp erről a folyamatról szól; arról, hogy az adatosodás, a hálózatba rendeződés, majd az adatokon alapuló előrejelzés mára mennyire jelen van az életünkben, és mennyire nem tudjuk kikerülni. Ennek demonstrálására Janosov a könyv múlt csütörtökön a CEU-n tartott bemutatóján azt vezette végig, hogy a közönségnek küldött kérdőív kérdéseire adott válaszok szerint milyen könyveket olvasnak szívesen az ott ülők, és az érdeklődésük alapján hogyan rendezhetők hálózatba.
Adatlapátolás két kézzel
Janosov a könyvbemutató előtt kérdésünkre elmondta: mindig is nagyon élvezte, amikor tudományos tényeket és eredményeket tudott lefordítani közérthető formátumba, elsődleges célja tehát az ismeretterjesztés. A világhírű hálózatkutató, a könyvet ajánló Barabási Albert László szerint a DATA adatorientált, részletgazdag írás, ami eltér attól, ahogyan ő dolgozik: míg ő fentről lefelé, Janosov inkább lentről felfelé építkezik.
A DATA így annak a leghasznosabb, aki még sosem foglalkozott adatokkal, hálózatokkal, és életszerű, részletgazdag példákon keresztül, néhány adat- és hálózattudományi alapfogalom megismerésével a nulláról szeretne képbe kerülni. Aki viszont már elkezdett foglalkozni azzal, hogyan gyűjtik a nagy techcégek az adatait, mi az a profilozás, és mit tehet az adatai védelméért, annak a könyv első, bevezető harmadában a példák lehetnek érdekesek.

A kötet például igyekszik megmagyarázni, hogy az adataink alapján hogyan rajzolják meg a profiljainkat a közösségi oldalak, és mi magyarázhatja azt a jelenséget, hogy ha egy baráti sörözésen a robotporszívók kerülnek szóba, akkor másnap robotporszívós hirdetéseket dob fel a Facebook vagy az Instagram. Igaz, a szerző szégyenlősen elzárkózik a konkrét állásfoglalástól abban az ügyben, hogy tényleg lehallgat-e minket a telefonunk, vagy ennyire jól megy ezeknek a cégeknek a profilépítés – inkább hajlik arra, hogy a hirdetési motorok precíz és állhatatos munkája áll a háttérben, nem a 0-24 órás megfigyelés.
Janosov olyan eseteket is felvonultat, mint az a híres-hírhedt történet, amikor az amerikai áruházlánc, a Target marketingesei olyan algoritmust építettek, amellyel a várandós kismamákat igyekeztek megcélozni és kitalálni, kinek küldjék e-mailben a mosható pelenkákra és egyéb baba-mama-termékekre vonatkozó kuponajánlataikat. Egy tizenéves lány apja felháborodva kereste meg a Targetet, hogy az ő lánya nem terhes, mégis ilyen leveleket kap - majd kiderült, hogy a lány tényleg gyereket vár, csak nem közölte vele a hírt. (A történet jól hangzik, bár Colin Fraser, a Meta egyik adattudósa szerint valószínűleg nem igaz.)
Hogyan lesz az adatból hálózat?
A könyv a továbbiakban a hálózatok természetéről szól és arról, hogyan lesz az adatból hálózat, és mihez kezdhetünk vele. Janosov ezt olyan, korábbi munkáiból már ismert példákon keresztül szemlélteti, mint a Trónok harca sorozatból készített elemzése, amelyben azt próbálta az adatokból előre jelezni, hogy melyik szereplő milyen valószínűséggel fog meghalni a sorozatban. Ehhez felrajzolta a szereplők közötti társadalmi hálót annak alapján, hogy ki kivel, hányszor és milyen hosszan folytatott párbeszédet, ennek alapján felrajzolta a Trónok harca világának társas hálózatát, majd a karakterek által betöltött pozícióból próbált következtetni a halálesetekre. Erről a munkájáról korábban a 444 számolt be, ahogy arról is, hogy Janosovnak végső soron elég jól sikerült eltalálnia, kinek vannak megszámlálva a napjai a sorozatban. Az adattudós saját számításai szerint egyébként 73 százalékban találta el a helyes választ.

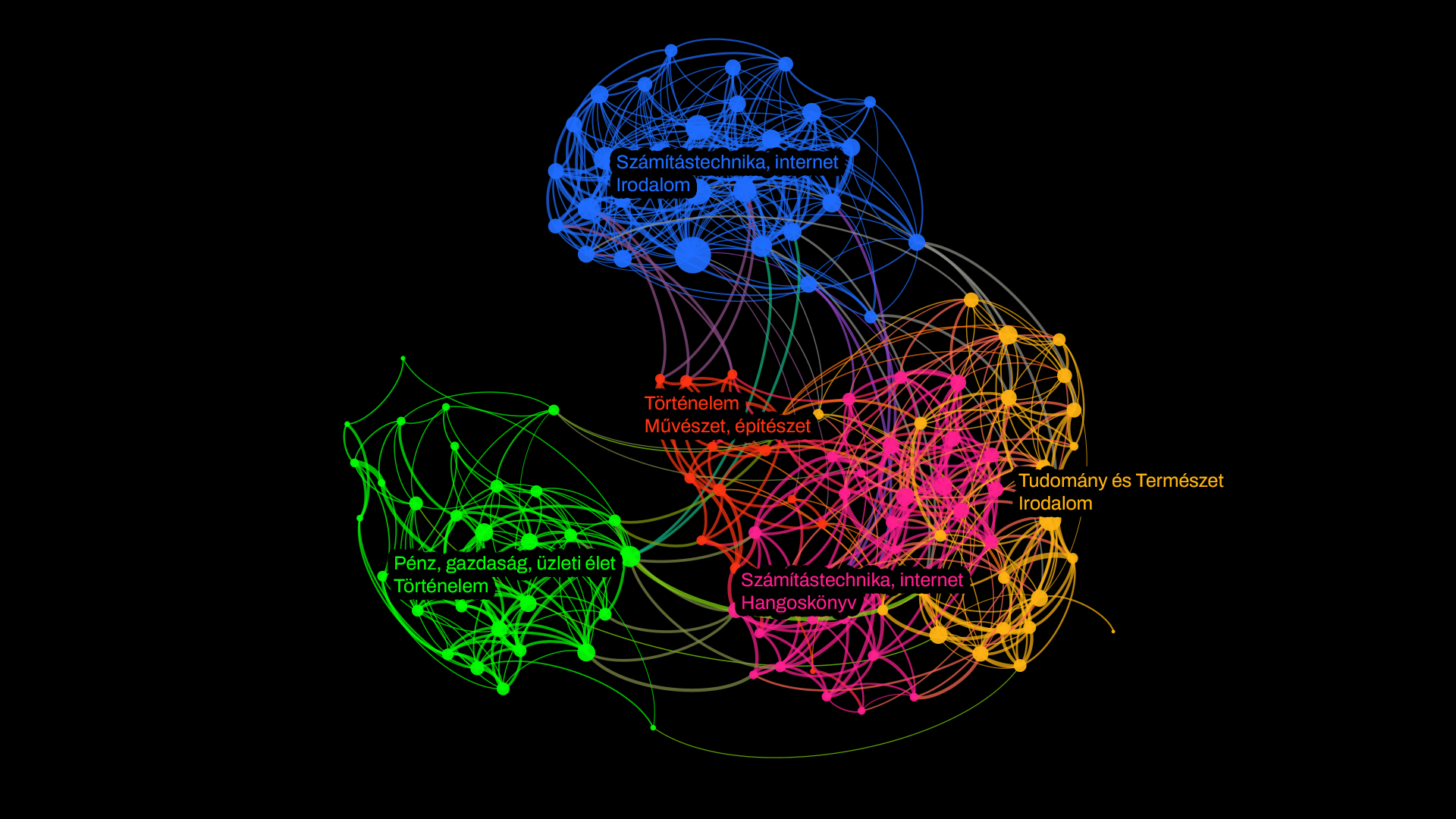
Amit mindenesetre az ehhez hasonló színes példák ellenére is lehet hiányolni a könyvből, az éppen Janosov erőssége, a szépen megrajzolt, vizuálisan erős ábrák. Azok az impresszív, színes és nagyméretű adatvizualizációk, amelyek már első pillantásra érzékeltetik, milyen hatalmas adatkészletből dolgozott a kutató, hogyan kapcsolódnak egymáshoz az adatpontok, és mennyire máshogy is el lehet mesélni az adatokból kirajzolódó történeteket a vizualitás nyelvén, mint szövegben vagy táblázatokban.
Egy korábbi ilyen projekt során Janosov felfestette a brit DJ-ügyi szakfolyóirat, a DJ Mag Top 100-as listáján szereplő DJ-k kollaborációs kapcsolati hálóját, ahol a zenészeket a csúcsok, a közös munkásságuk erősségét pedig a köztük futó élek jellemzik. A különböző színek különböző alkotói közösségeket jelölnek, míg a csúcsok mérete arányos a sikerességükkel:
Milyen gyorsan terjednek az álhírek?
A könyvben felsorakoztatott példák közül azok tűnnek a legérdekesebbnek, amikor Janosov adatok és hálózatba rendeződés alapján igyekezett szabályt alkotni arra, hogy kikből lesznek a top DJ-k, vagy amikor egy konkrét cég munkatársainak belső hálózatba rendeződése alapján megállapította, melyik az a munkatárs, akinek kulcsszerepe van a nem hivatalos információáramlásban, és hogy miként lehet felrajzolni egy ilyen hálózatot. Az izgalmas projektek között volt az a kutatás is, ami azt vizsgálta, hogy mennyire nehezíti meg a tömegközlekedést a Lánchíd lezárása, vagy hogy mi az oka annak, hogy az álhírek sokkal gyorsabban terjednek, mint a hiteles, megbízható sajtóinformációk.
Ez utóbbiról Janosov elmondta: „Ez egy MIT-s csapat munkája volt, akik azt találták, hogy az álhírek a Twitteren nagyjából tízszer annyi embert tudnak elérni, és hétszer akkora sebességgel terjednek [mint a valódiak]. Szóval sokkal messzebbre jutnak, és sokkal hamarabb. A hipotézisük erre az volt, hogy ezek az álhírek valószínűleg sokkal-sokkal meglepőbbek, innovatívabbak vagy formabontóbbak, mint a valódi hírek. És egyszerűen az emberek ennyivel fogékonyabbak valamire, ami meghökkentő, attól független, hogy egyébként egyáltalán nem biztos, hogy igaz.”
Kapcsolódó cikkek a Qubiten:

Barabási Albert László: „A ChatGPT algoritmusa egyszerre elegáns és primitív”
Mennyibe kerül Magyarország összes lakosának minden GPS-adata egy hónapra? Mit tud a ChatGPT, amit korábban más nem tudott? Hogyan segített a hálózatkutatás a covid legyűrésében? Aki válaszol: Barabási Albert László és Janosov Milán hálózatkutató, akinek új kötetét csütörtökön mutatták be a CEU-n.
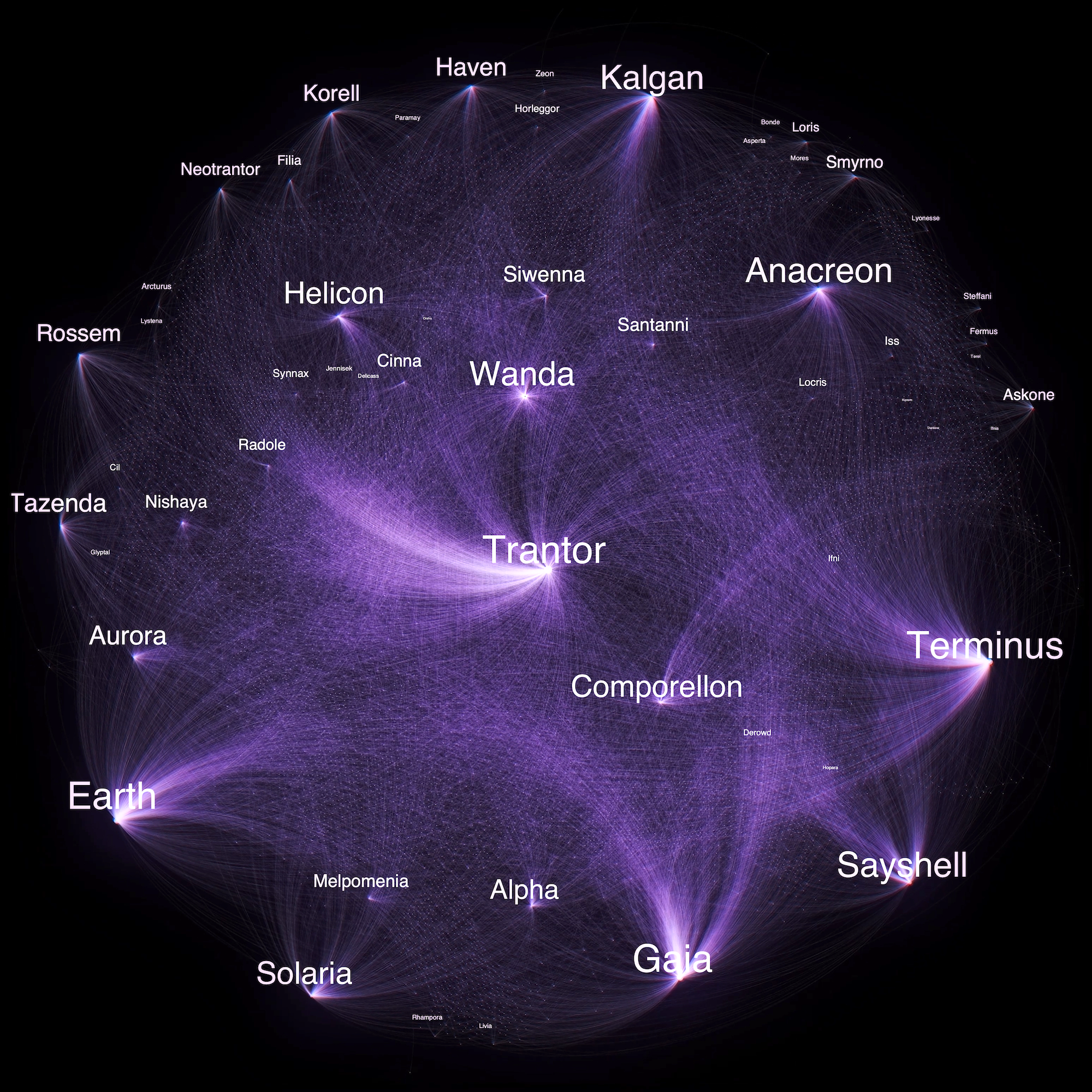
Hálózattudományi eszközökkel készített digitális műalkotást Asimov Alapítvány-sorozatából egy magyar kutató-művész páros
Janosov Milán és Borsi Flóra 8 375 csomópontot és 22 299 kapcsolatot bemutató animációja feltárja a hétkötetes regényfolyamban szereplő bolygók közötti kapcsolatokat és a mű szerkezetét. 4,2 ethereumért vihető!

Magyar hálózatkutató eredt nyomába a kínzó kérdésnek, hogy mitől lesz sztár egy DJ
Janosov Milánéknak a Scientific Reportsban megjelent tanulmánya szerint a legnagyobb sztárok által mentorált fiatal DJ-k átlagosan sokkal sikeresebbek lesznek, mint nem mentorált társaik. A mentorálásnak azonban árnyoldala is van: az ifjú padavánok tipikusan sosem érik el világklasszis mesterük sikereit.
