Barabási Albert László: „A ChatGPT algoritmusa egyszerre elegáns és primitív”

– A koronavírus-járványnak felbecsülhetetlen reklámereje volt a hálózatelmélet népszerűsítésében: a családi vacsorák egy időben terjedési folyamatokról, reprodukciós rátákról és kontaktkutatásról szóltak. A covid elmúlt, de jó lenne, ha a hálózatos gondolkodás megmaradna, hiszen rálátást ad a körülöttünk zajló folyamatokra – mondta Barabási Albert László világhírű hálózatkutató és fizikus csütörtökön a Hálózatok éjszakáján a CEU-n, ahol kollégája, Janosov Milán hálózatkutató, nem mellesleg a Qubit állandó szerzője mutatta be DATA - Így hálóznak be az adataid című új könyvét.
Azon túl, hogy Janosov könyve a tudománynépszerűsítés jegyében közérthető módon meséli el, hogyan lesz az Instagramra kirakott reggelinkből adat, és hogyan rendeznek minket ezek az adatok hálózatba a többi filterkedvelő felhasználóval együtt, azt is bemutatja, hogyan működik az adatalapú előrejelzés.
„Az adatokból azért lehet jósolni, mert nem függetlenek, hanem erősen korrelálhatnak egymással. Ha a belső törvényszerűségeiket feltárjuk, bizonyos, egyébként véletlennek tűnő jelenségek nyilvánvalóvá válnak” – mondta erről Barabási. Szerinte az adatokban ugyanúgy ott a következő lépés, mint a rövid távú időjárás-jelentésben: ahogy ma már tudjuk, hogy holnap milyen időre számíthatunk, azt is tudjuk, hogy körülbelül két hétre előre lehet megjósolni az időjárást. „Az adattudomány értelme az, hogy kihalássza azokat a jelenségeket, amelyeket meg lehet jósolni, és megmondja a jóslás határát is”.

A két kutatót a frissen megjelent könyvről, emellett a manapság legfelkapottabb hálózatos témákról, adatgyűjtésről, adatvédelemről, mesterséges intelligenciáról, ChatGPT-ről és járványterjedésről kérdeztük.
Qubit: A könyv első fele a minket körülvevő adatokat tárja fel, majd megnézi, hogyan rendeződnek hálózatba. Milyen újdonságot mondott önnek mint hálózatkutatónak a könyv?
Barabási: Először is ez egy nagyon adatorientált könyv. Én inkább arról szoktam írni, hogyan működik a világ, Milán pedig azt bontotta le, hogy ez most mit jelent nekünk. És hogy igazából hol vannak körülöttünk részletesen és konkrétan mindazok a dolgok, amik behálóznak bennünket. Ilyen szempontból teljesen más perspektívát ad arról, amiről én is szeretek beszélni; mondhatni azt, hogy én fentről lefelé, ő pedig lentről felfelé építkezik. És ez logikus is, mert az adat szempontjából közelíti meg a dolgokat, és hogyha onnan közelítesz, akkor a részletek nagyon-nagyon fontossá válnak. Ha arról van szó,, hogy konkrétan hol van adat, és milyen módon lehet erről beszélni, akkor az egy teljesen más szakmává válik.
A Trónok harca, Tiesto és a hollywoodi hírességek mellett előkerül a könyvben az adatműveltség kifejezés is. Ez mit jelent pontosan?
Janosov: Teljes könyvek szólnak arról, mi is az adatműveltség. Én leginkább az üzleti, a vállalati és a techszférában szoktam hallani, és ott leginkább az a kontextus, hogy egy cégen belül a munkatársak, a döntéshozók, az informatikusok képben legyenek, és tudják, milyen adatvagyonuk van, milyen potenciál rejlik benne, és mit lehet belőle kihozni. De igazából ugyanezt tudjuk általánosítani hétköznapjainkra is, mert ugye ott van nálunk a telefon, a laptop és egyéb kütyük. Ezek rengeteg dolgot meghatároznak: milyen eseményeket dob fel a Facebook, mely ismerőseinkkel találkozunk újra, hogyan vásárolunk online, mennyi pénzt költünk. És mivel számtalan olyan dolog van a hétköznapjainkban, amiket az adatok meghatároznak, egyre fontosabb az, hogy szinte mindenki, aki telefont, Facebookot használ, belelásson abba, mi zajlik a háttérben, mi történik saját adataival.
Mára, főleg Európában, elkezdték szigorúbban szabályozni, hogy ki milyen adathoz hogyan férhet hozzá, de a mindennapokban inkább az adatgyűjtés előnyeivel találkozunk, miközben az adatvédelemmel hadilábon állunk. Mit gondol erről?
Janosov: Igazából a szellemet már kiengedtük a palackból – már nem igazán reális opció, hogy valaki ne facebookozzon vagy nem e-mailezzen. Érdekes kérdés, hogy a GDPR [az EU adatvédelmi rendeletcsomagja] vajon jó-e vagy sem. Többnyire én is azt látom, hogy inkább gyakorlati nehézséget jelent, amikor például adatokat szeretnénk vásárolni vagy feldolgozni, de valószínű, hogy a más kontinenseken féktelenül zajló szabad adatrablást mégiscsak meggátolja.
Mert például egy GDPR-ral nem rendelkező országban vagy földrészen simán előfordulhat az, hogy valaki rengeteg személyes, mondjuk egészségügyi adatot is értékesít, és így egy biztosítótársaság a teljes egészségügyi történetünket megvásárolhatja, akár tudtunkon kívül is, mert bekerült egy adatpiacra. És az például nem biztos, hogy jó nekünk, ha annak alapján fognak minket biztosítani, hogy a családban korábban milyen betegségek voltak.

Kutatóként mennyire nehéz adatokhoz hozzáférni?
Janosov: Az óriási techcégek gyakorlatilag ülnek az adatainkon, és ezek kívülről szinte hozzáférhetetlenek. Én azt látom, hogy nagyon sok esetben nemcsak kutatóként, hanem akár cégként is rengeteg falba lehet itt ütközni, pedig ezek sok esetben tőkeerősebb entitások, mint egy kutatócsoport. Szóval egy adatgyártó cég tipikusan foggal-körömmel védi és körbebástyázza az adatait. Általában a teljes adat valamilyen kis részhalmazát értékesítik, mint a Twitter, vagy valamilyen aggregált formátumát, mint például a telekommunikációs cégek. A Twitteren például, vagy amit egy-két héttel ezelőtt még Twitternek hívtak, elég sok, nagyságrendileg 0,5 százaléknyi adat volt ingyenesen és transzparensen elérhető a kutatóknak, de sok más cég, ha árul is adatokat a sajátjaiból, jellemzően nagyon drágán adja őket.
Hogy képzeljük el nagyságrendileg, mennyibe kerül egy ilyen nagy adatbázis, amin egy kutató vagy egy kutatócsoport dolgozhat?
Janosov: Kedvenc példám erre a GPS-adat. Nagyon sok applikáció fut a telefonunkon, ami rögzíti, hogy hol vagyunk. A navigációs appok, a Twitter vagy a hírportálok egy csomó lokációs információt vesznek fel, ami tényleg azt jelenti, hogy tudják, mikor hol vagyunk. Utána ezt anonimizálják, szóval már csak az szerepel, hogy az XYZ azonosítójú felhasználó ma itt volt a CEU-n. Ez eléggé szürke zóna, és vitáznak is a jogászok arról, hogy egy ilyen útvonal, amit leírunk, mennyire személyes adat. Ez egyrészt csak egy pontsor; másrészt viszont, ha melléteszünk bármilyen infót, amivel tudjuk azonosítani, hogy mi kik vagyunk, például elmegyünk egy konditerembe, és ott lecsippantják a kártyánkat, akkor már egyből nagyon durva személyes adattá válik, mert látszik, hogy hol lakunk, hol járunk, mit csinálunk. Vannak olyan cégek, amik több ezer applikáció gyártójával vannak szerződésben, és tonnaszámra veszik tőlük ezeket az adatokat.
Ami az adatok árát illeti, bár nem frissek a számok, mondjuk 1-1,5 évvel ezelőtt Magyarország lakosságának 2-3 százalékának összes GPS-adata egy hónapra 5-6 ezer dollárba (1,7-2,1 millió forint) került. Egyhavi adat már jó lehet valamire, de ha igazán nagy projektet akarunk csinálni több országra vonatkozóan, akkor ebből sok kell, ami már csillagászati összegeket is jelenthet.

Könyvében említi Kurt Vonnegut amerikai író elméletét, aki olvasmányai alapján nyolc módját írta le annak, ahogyan az írók általában végigvezetik a történeteket. Évtizedekkel később jött egy csapatnyi adat- és hálózattudós, akik több ezer könyvön vizsgálták meg, mennyire állja meg a helyét ez az elmélet. A technológia fejlődésével párhuzamosan úgy tűnik, mintha az adatvezérelt szemlélet egyre jobban dominálna, és inkább az adat kell először, nem az elmélet. Mi igaz ebből?
Janosov: Én azt látom, hogy két irányra bomlik a világ. Van egy társaság, akik szerint az elmélet a legfontosabb, és ha van adatunk, akkor jó, de egyébként az elmélettel is sokáig boldogok lehetünk. A másik oldal pedig az adatból indul ki, és hogyha van adat, akkor indulhat a felfedezés. Egyébként itt látok korrelációt a humán és a reál, szociológus és fizikus háttér között. Szerintem kétpólusú világ alakult ki a tudományban.
Barabási: Igazából én sokszor úgy gondolkozom ezen, hogy ha van egy belső törvényszerűség, amit fel kell fedezni, akkor az elmélet nagyon fontos. Tehát akármennyi adatunk van, előbb-utóbb F=m*a, vagyis a gravitáció törvénye lesz belőle. A tudomány egyik elsődleges célja az, hogy a gravitációs törvényt, Newton törvényeit, a gázok törvényeit felfedezzük, mert valahol ott van a valóság elrejtve. De ez általában együtt létezik sok-sok más faktorral.
Ugye ha kidobunk valamit az ablakon, akkor az nem fog gravitációs gyorsulással folyamatosan gyorsulni, hanem konstans sebességre fog beállni. Ebből valaki levonhatja azt a következtetést, hogy a gravitációtörvény hibás. De igazából nem erről van szó, hanem arról, hogy létezik súrlódás és levegő. Ha légüres térben csinálnánk, akkor pont úgy működne, ahogy Newton törvényei kimondják. A valóság mindig abból áll össze, hogy vannak az alapvető törvények, amelyek mindenkire hatnak. Viszont ezen kívül még egy csomó más effektus jelen van. És ha ezek bonyolulttá és kezelhetetlenné válnak, akkor jön a képbe a big data, ahol különböző eszközökkel részben ki lehet szűrni a törvényeket, és részben szét lehet válogatni a különböző effektusokat. Namost a társadalmi jelenségekben lehet, hogy van F=m*a, tehát lehet, hogy van néhány alapvető törvényszerűség, de annyi minden történik egyszerre, olyan sokrétegűek ezek a folyamatok, hogy ha nem járjuk őket körül adatokkal teljes részletességben, akkor hiába van meg az alaptörvényszerűség, úgy járunk, mint Newton törvényével, hogy beáll a konstans sebesség, és nem fog gyorsulni a dolog.
Egy interjúban beszélt arról, hogy ahhoz, hogy a hálózattudomány kialakuljon, arra is szükség volt, hogy megjelenjen a technológiai háttér, az internet vagy a nagy méretű adathalmazok. Azóta megjelent az AI, annak is a generatív formája, például a ChatGPT. Ez hogyan hat a hálózattudományra?
Barabási: Mi a laborban már évek óta használjuk a különböző AI-eszközöket. Konkrétan mielőtt eljöttem volna Budapestre, az előző hónapban a laborban teljesen szétszedtük a ChatGPT algoritmusait. Próbáltuk megérteni, hol van az extra prediktív erő benne, és mi az, amit a további algoritmusok nem tudtak. És nem azért, mert jobbat akarnék csinálni belőle, hanem hogy kiderítsük, milyen más problémákra lehetne alkalmazni azt a gondolkodást meg azt az AI-algoritmust, ami mögötte van, mert ott nyilvánvalóan volt előrelépés az AI szintjén is. Úgyhogy ez egy eszköz, ami beépül a munkába, de persze lehet cél is.
Janosov: Igen, a kulcsszó az, hogy ez egy eszköz. Nagyon sokan megijednek attól, hogy majd elveszi a munkánkat, de ilyet már sokszor láttunk más új technológiákkal. Egyik kedvenc példám a könyvelők és az Excel. Ott is biztosan ijesztő volt, mennyivel gyorsabban lehet dolgozni Excelben, a könyvelőknek mégis azóta is van állásuk. Ezt látom a ChatGPT-vel is. Én napi szinten egyre többet használom, mondjuk programozás és adatelemzés közben. Például meg szoktam kérni pár sornyi kód megírására. Általában nem tökéletes, vannak benne még ilyen kis gyermeteg bakik, de nagyon sokat gyorsít a munkán. Szóval egy feladat elvégzése mondjuk négy óra helyett egy óra.
Említette, hogy szétszedték a laborban a ChatGPT-t. Azt lehet tudni, hol van az extra prediktív erő benne?
Barabási: Hogyne, hogyne, és ez nem titok. Amit az emberek elfelejtenek, az az, hogy maga az algoritmikus előrelépés a kilencvenes évek közepén és végén történt. Tehát ami a ChatGPT-ben van, az nem egy drasztikusan új módszertan. Ami drasztikusan megváltozott, az a tréningelés, vagyis az adatmennyiség, amire szükség volt ahhoz, hogy ezeket a problémákat „feltréningeljék”. Ezen kívül a ChatGPT-ben és a hasonló módszerekben megvan a korreláció nagyon finom és nagyon okos kezelése. Minden mindennel össze van kapcsolva valamilyen módon, de kontextus függvényében kell nézni azt, hogy én az azt szót most miért mondtam, mire utal a mondatban. És sok helyen lehet az azt szót látni mondatokon belül, de a jelentése nagyon attól függ, hogy milyen kontextusban jelenik meg.
És ezt a ChatGPT egy úgynevezett figyelem- vagy attention mechanizmus segítségével nagyon pontosan tudja kezelni. Tehát a kontextus függvényében tud jóslásokat tenni, ami egyébként nagyon hasznos minden más környezetben is – nemcsak a nyelven belül, bár ott lehet a legjobban demonstrálni. Tehát történt egy finom előrelépés, viszont az igazán nagy áttörés az volt, hogy most ekkora adatmennyiségen lehet tréningelni, úgyhogy nekem a sejtésem az, hogy most egy platóra értünk. Megtörtént ez a nagyon nagy ugrás, ez kétségtelen, hogy mindenki megijedt tőle, és most úgy képzeljük, hogy ez így fog menni tovább. Szerintem nem. Ezt most egy kicsit megszokjuk, és lehet, hogy 3 év, 10 év vagy 20 év múlva lesz még egy minőségi ugrás ebben a sztoriban. Különösen miután szétszedtük az algoritmust, megdöbbentőnek találtuk, mennyire elegáns, ugyanakkor mennyire primitív. Mindaz a mesterséges intelligencia, amire gondolunk, az nincs benne. Elég egyszerű mátrix-manipuláció van mögötte.
Azt is mondta, hogy a ChatGPT prediktív ereje picit jobb, mint a többi eszköznek, és ha jól láttam, a BarabásiLab fontos eleme a predikció. Egyik kollégája, Alessandro Vespignani a vírusterjedés hálózatos vizsgálata során már 2019 decemberében meg tudta mondani, hogyan robban majd be a covidjárvány. Azt is megnézték, hogy fog a pandémia lecsengeni, vagy a terjedést könnyebb vizsgálni, mint mondjuk azt, amikor elhalnak a hálózatok?
Barabási: Sokkal könnyebb vizsgálni a terjedést egy olyan rendszerben, amikor még nem reagál senki semmire. És ez volt az a korai állapot, amikor Vespignani és csapata nagyon pontosan megjósolták, hogy mekkora baj lesz, ha nem reagálunk. És amit lényegében a vakcinák megjelenése után csináltak, azzal folyamatosan azt prediktálták, hogy ez hogyan fog eltűnni, és hogy milyen intervenciókkal minimalizáljuk az impaktját. Tehát, tényleg nagyon megváltozott a feladatuk, különösen amikor megjelent a vakcina, mert akkor már lényegében teljesen arról szólt minden, hogy miként menedzseljük ezt az egész folyamatot, hol kell még esetleg odafigyelni, milyen mértékben, hol fog eltűnni, milyen korosztályok életét fogja még mindig befolyásolni.
Ők a mai napig foglalkoznak ezzel. Most már egy kicsit áttértek az új vírusokra, mert jött néhány új vírus az utóbbi időben, és azokat jósolják, de a feladatnak mind a kettő a része volt. Az elején, amikor [Vespignani] 2019 decemberében már mondta, hogy ebből nagyon komoly problémák lesznek, amikor még tényleg senki se figyelt oda, akkor tényleg egy teljesen perturbációmentes rendszert nézett: senki sem volt hajlandó megváltoztatni a viselkedését, ergo a vírus úgy terjedt, ahogy tudott. Abban a pillanatban, hogy megtörtént a lezárás, már teljesen más problémával álltak szemben. Az elején az volt a kérdés, hogy mi az, amit a leghamarabb meg lehet nyitni, iskolát, bárt vagy munkahelyet, utána az, hogy ki kapja meg leghamarabb a vakcinát, és lényegében az egésznek a menedzselése. Abban segítettek a kormányoknak, hogy ennek a mechanikáját kitalálják.
Janosov: A másik fele a kérdésnek, hogy a felfutást vagy a lecsengést könnyebb-e vizsgálni. Ez szerintem nehéz kérdés, de az biztos, hogy nagyon sokan foglalkoznak azzal, hogy milyen a kollektív felejtés. Mert úgy tűnik, hogy ez kétmóduszú dolog: jön a nagy hype, amikor mindenki figyel rá, aztán szép lassan kezd lecsúszni, utána viszont nagyon sokáig, de nagyon kis intenzitással még jelen van. Ez egyébként nagyon sok helyen megjelenik a zenétől a könyvpiacon át egészen a közösségi médiáig. Ott is azt látjuk, hogy ha kiposztolunk valamit, akkor hirtelen aznap rengeteg like jön, aztán jövő héten már igazából senki nem is emlékszik rá.
Kapcsolódó cikkek a Qubiten:

Magyar hálózatkutató eredt nyomába a kínzó kérdésnek, hogy mitől lesz sztár egy DJ
Janosov Milánéknak a Scientific Reportsban megjelent tanulmánya szerint a legnagyobb sztárok által mentorált fiatal DJ-k átlagosan sokkal sikeresebbek lesznek, mint nem mentorált társaik. A mentorálásnak azonban árnyoldala is van: az ifjú padavánok tipikusan sosem érik el világklasszis mesterük sikereit.

A 21. századi jövendőmondó nem a vízbe vetett ólomból jósol, hanem száraz adatokból
Magyarul most megjelent könyvéről, a koronavírusról és a hálózati modellekről beszélgetett csütörtökön Alessandro Vespignani hálózatkutató, fizikus Barabási Albert-Lászlóval. A jóslás algoritmusa nem a COVID-19-ről szól ugyan, de az algoritmusokat a vírus ellen is hatékonyan be lehet vetni.
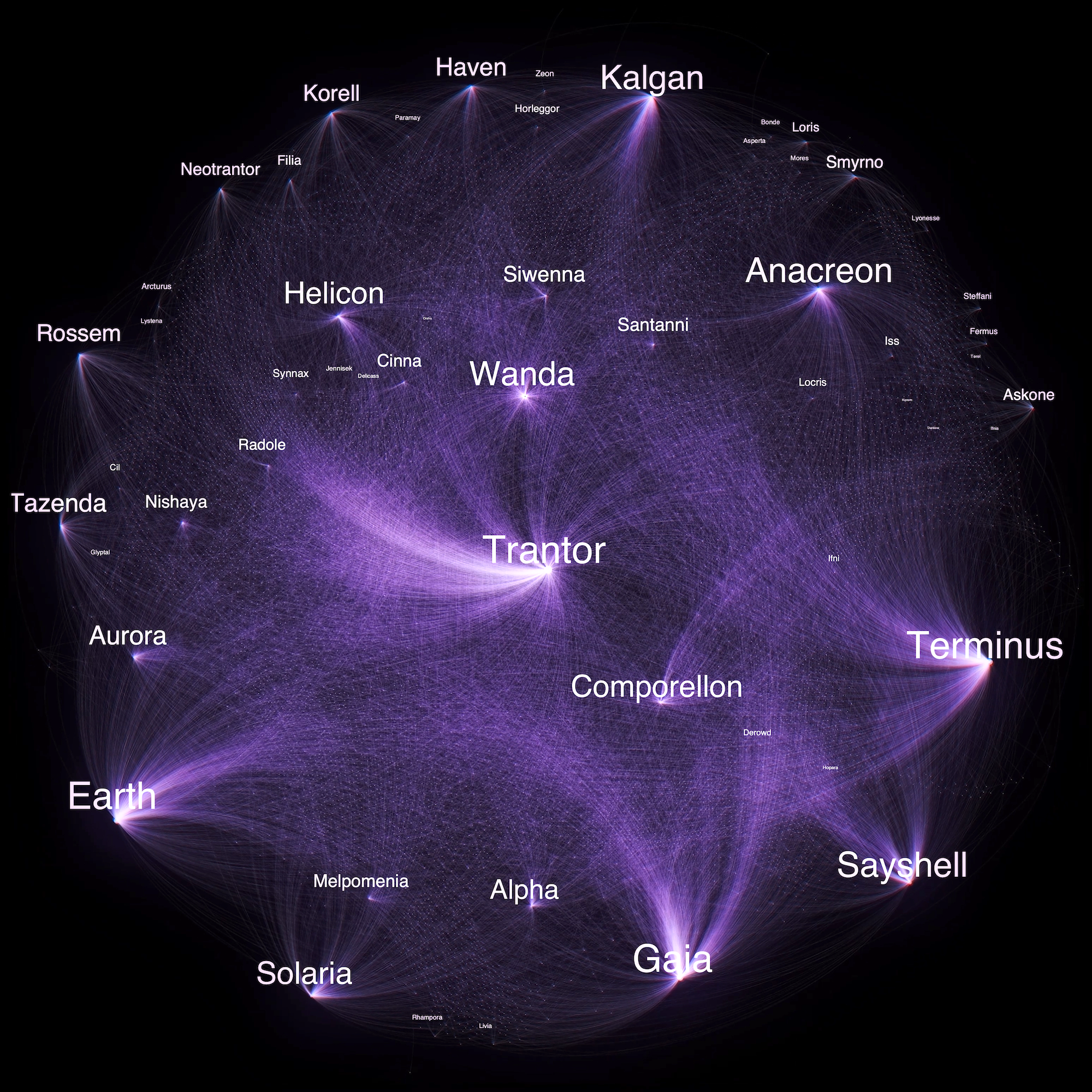
Hálózattudományi eszközökkel készített digitális műalkotást Asimov Alapítvány-sorozatából egy magyar kutató-művész páros
Janosov Milán és Borsi Flóra 8 375 csomópontot és 22 299 kapcsolatot bemutató animációja feltárja a hétkötetes regényfolyamban szereplő bolygók közötti kapcsolatokat és a mű szerkezetét. 4,2 ethereumért vihető!

