Felrobbant az internet péntek este: Sam Altmanék bemutatták az o3-at

Jókora lépéssel közelebb került a mesterséges általános intelligenciához (Artificial General Intelligence, AGI) az OpenAI. A ChatGPT-t kifejlesztő amerikai cég pénteken rukkolt elő új, o3 nevű modelljével, amely az emberéhez hasonló teljesítményt ért el egy elismert, általános intelligenciát vizsgáló AI-teszten, amihez hasonlóra egyetlen korábbi modell sem volt képes.
Az o3 az idén szeptemberben debütált o1 második generációs verziója, amit a cég a brit O2 mobilszolgáltató miatt volt kénytelen a kettes helyett a hármas számmal jelölni. Ezek a modellek a GPT-4o-hoz és a legtöbb nagy nyelvi modellhez (LLM) képest jobban „átgondolják” a válaszaikat, így nehezebb matematikai, tudományos és programozási feladatokkal is elboldogulnak. Definíciója szerint az AGI számos feladat elvégzése során eléri vagy meghaladja az emberi kognitív képességeket, és képes megtanulni bármit, amit az ember.
„Ezekre az AI-fejlesztések következő fázisának kezdeteként tekintünk, amelynek során a modellek egyre komplexebb, alapos átgondolást igénylő feladatok megoldására lesznek használhatók” – mondta Sam Altman, az OpenAI vezérigazgatója a cég pénteki, élőben közvetített bejelentése során.

Az o3 modellcsalád az o1-hez hasonlóan két verzióból, a legfejlettebb, és valószínűleg nagyon költséges o3-ból és az olcsóbban futtatható o3 mini-ből áll. „Az a tervünk, hogy az o3 mini-t január vége körül tesszük elérhetővé, míg a teljes o3 modellt nem sokkal utána” – mondta Altman.
Az o3 bemutatása koronázta meg az OpenAI 12 munkanapon át tartó bejelentéssorozatát, (12 Days of OpenAI), amit december elején kezdett a cég. Az első napokban a havi 200 dolláros ChatGPT Pro előfizetés debütált, majd elérhetővé vált – legalábbis Európán kívül – a Sora videógenerátor, és új funkciókat kapott a ChatGPT alkalmazás, amivel a chatbot hamarosan már a szelfikamerák képét vagy a képernyőkön megjelenő tartalmat is ki tudja elemezni, és egyre több másik alkalmazással tud együttműködni.
De nem sokon múlt, hogy a médiában „shipmas”-nek becézett marketingkampány vitorlájából kifogja a szelet a Google. A keresőcég december közepén elérhetővé tette Gemini 2.0 chatbotját (aminek ingyenesen használható Flash verziója jelenleg megelőzi az OpenAI o1 mini modelljét a Chatbot Arena ranglistán), bemutatta videógenerátorát, a Veo 2-t, és saját „gondolkodó” modelljének belépő szintű változatát, a Gemini 2.0 Flash Thinking-et. Emiatt a Redditen az AI-rajongók már temették az OpenAI-t, és a Google győzelmét vizionálták, amíg Altman csütörtökön az X-en (hol máshol?) meg nem megszellőztette, hogy másnap nagy bejelentésre készülnek.
Felülmúlta az embert egy általános intelligenciát mérő teszten
A péntek esti élő bemutatón Altman beharangozta az o3 modelleket, aztán átadta a szót Mark Chennek. Ekkor jött a lényeg, a cég kutatási igazgatója ugyanis elkezdett a modell képességeit bemutató teszt (benchmark) pontszámokat mutogatni – amiktől pillanatok alatt felrobbant az internet.
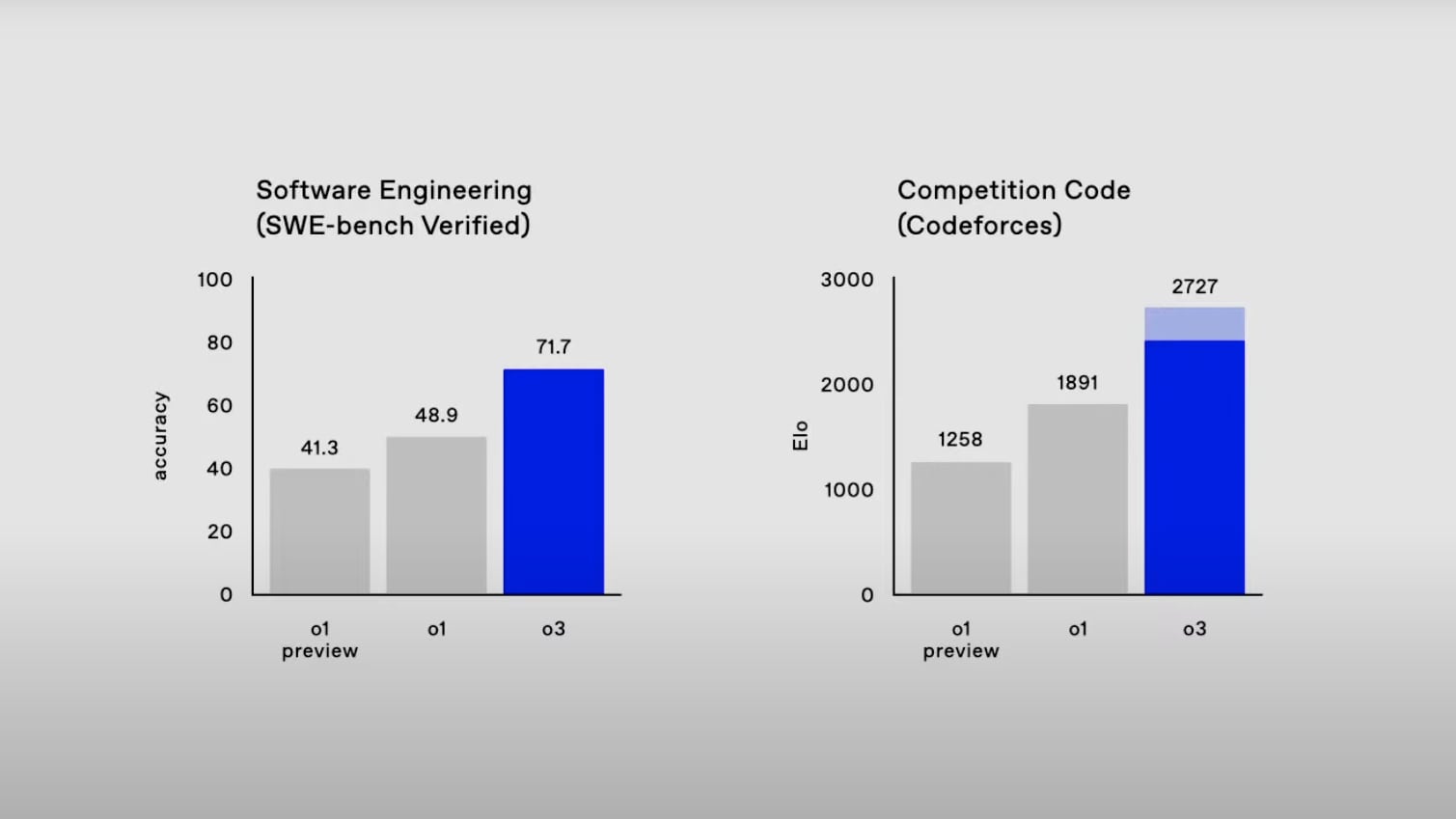
Chen először hagyományosabb tesztekkel kezdett, amelyekben az o3 40 százalékkal jobb pontszámot kapott az o1-nél. Közben érzékeltette, hogy ez mit jelent: az o3 Codeforces kódolási versenyen elért 2727-es pontszám magasabb, mint az OpenAI vezető kutatójáé. „Azt hiszem, van egy srác az OpenAI-nál, aki 3000 körül áll, amit még néhány hónapig élvezhet…” – tette hozzá Altman, arra utalva, hogy a modelljeik képességei hamarosan a legjobb programozóikét is lekörözhetik.
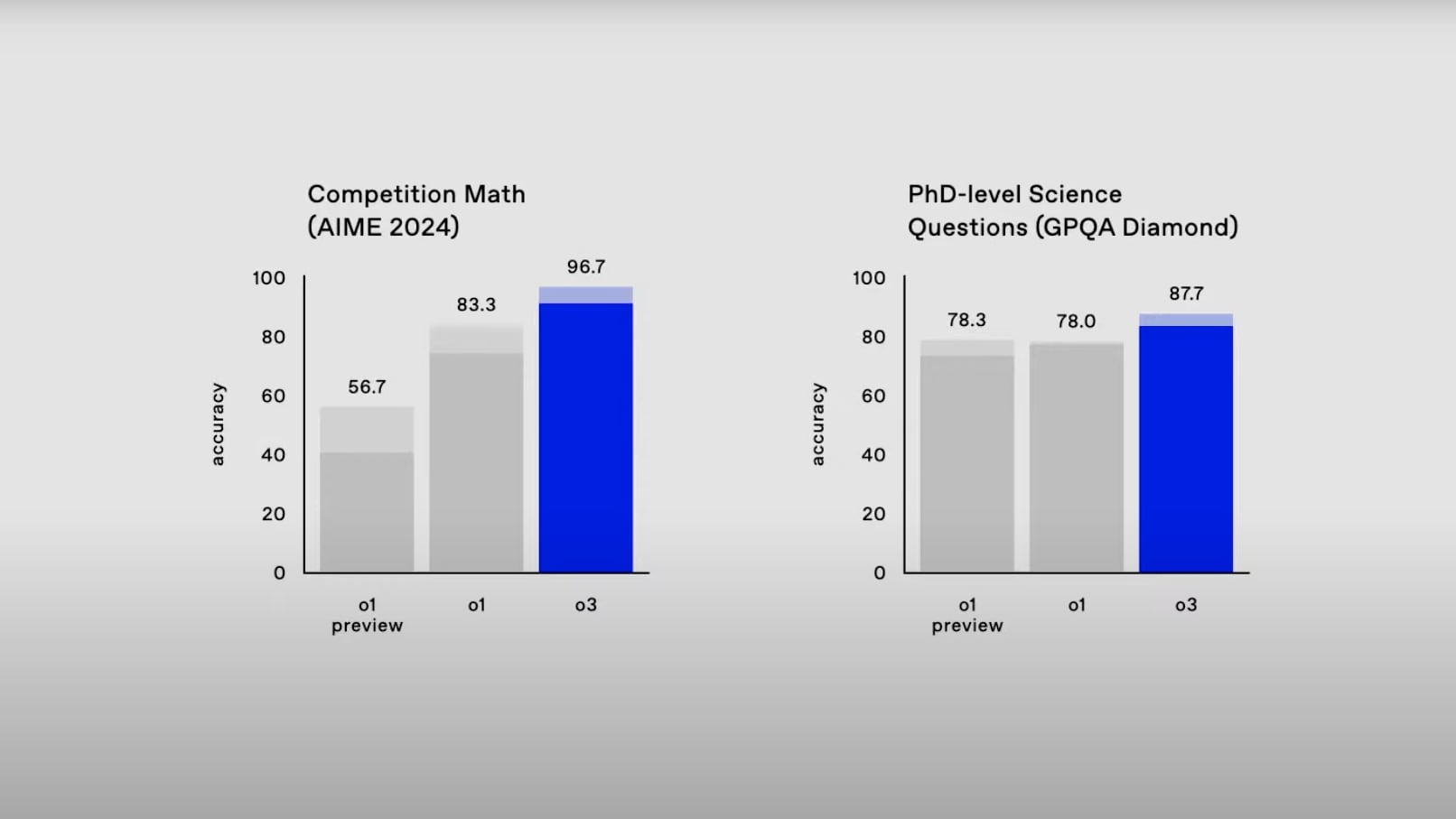
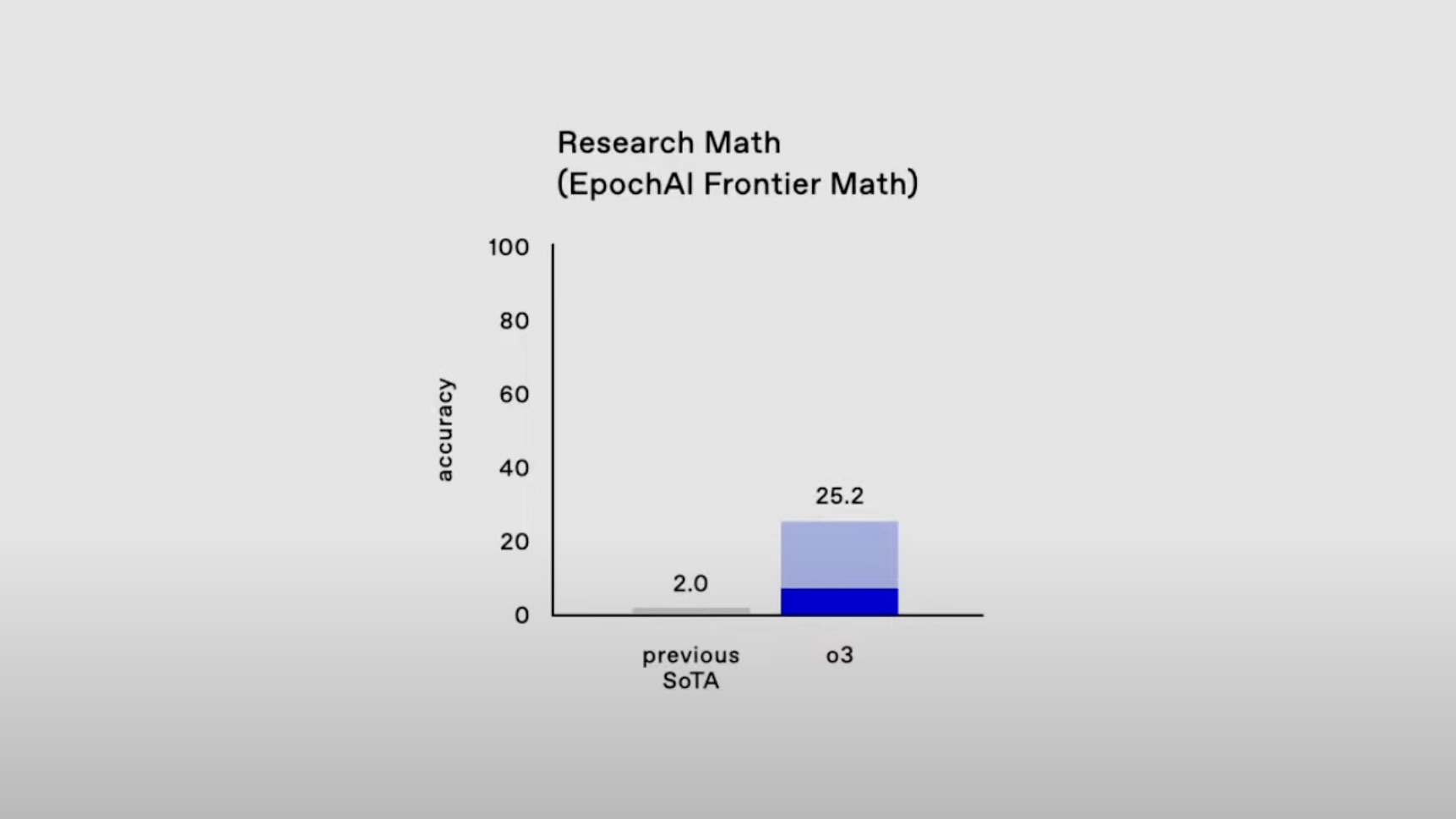
Az o3 nemcsak a kódolás terén mutat kiemelkedő képességet, hanem tudományos kérdéseket is pontosabban válaszol meg az o1-nél, ami már eleve jobb volt ebben egy átlagos doktorandusznál, akik a 100 pontból jellemzően 70-et érnek el saját területükről feltett kérdéseknél. „Az o3 kezdi túlszaturálni ezeket a benchmarkokat; nehezebbek tesztekre van szükségünk ahhoz, hogy a legfejlettebb modellek képességeit kipróbáljuk” – állapította meg Chen. Úgyhogy az Epoch AI FrontierMath tesztjével folytatta, amit Altmannal a létező legnehezebb matematikai tesztként mutattak be, ami még a világ legjobb matematikusait is megizzasztja. Az eddigi legjobb modellek, mint mondta Chen, 2 százaléknál gyengébb pontszámot értek el, az o3 viszont 25,2 százalékot tud, ami jelentős áttörés.
De ez még csak a bemelegítés volt, Chen ugyanis ezek után bemutatta az ARC Prize Foundation vezetőjét, Greg Kamradt-ot, aki kollégáival évekkel ezelőtt egy 1 millió dolláros díjazású versenyt indított, amin AI-modelleknek az általános intelligencia képességeket tesztelő, széles körben respektált ARC-AGI tesztjüket kell legyőznie. A teszt lényegét az adja, hogy az AI-nak példák alapján mintázatokat kell felismernie, majd ezt az információt új rejtvények megoldására kell használnia. „Tesztelni szeretnénk a modellek képességét arra, hogy élőben tegyenek szert új képességekre” – mondta.
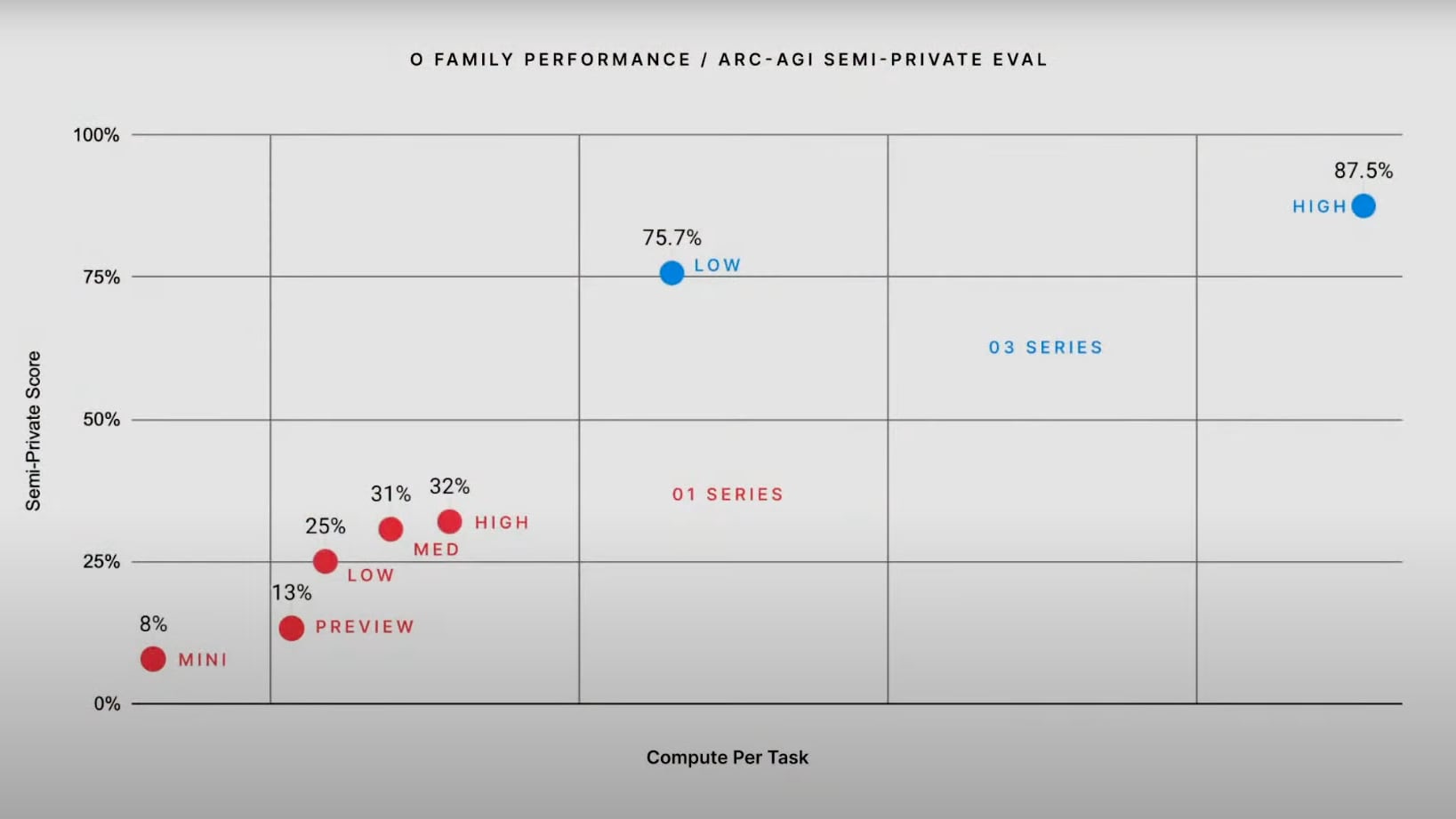
Az ARC-AGI teszten az o3 normál számítási idővel 75,7 százalékot, maximális számítási idő mellett pedig 87,5 százalékot ért el. Utóbbi pontszámot Kamradt elsőre elrontotta a bejelentés során, majd Altman gyorsan kijavította, nem véletlenül. „Az emberi teljesítmény a 85 százalékos küszöb körül alakul, vagyis ennek meghaladása jelentős mérföldkő” – mondta az alapítvány vezetője, aki hozzátette, hogy „soha nem teszteltünk még olyan modellt, ami erre képes”. Kamradt az absztraktnak tűnő teszt tágabb jelentőségéről is beszélt: „amikor ezeket a pontszámokat látom, rájövök, hogy kissé módosítanom kell a világképemet, újra kell gondolnom az intuícióimat arról, hogy a mesterséges intelligencia mit tud csinálni, és mire képes, különösen ebben az o3 által bevezetett világban”.
De mit mondanak az OpenAI-tól független szakértők? Ethan Mollick, a Pennsylvaniai Egyetem mesterséges intelligenciával foglalkozó professzora azt írta az X-en, hogy „bár még nem próbáltam az o3-at, és korábban kritikus voltam az AI-benchmarkokkal szemben, [az OpenAI] a legnehezebbek és legjobbak ellen tesztelte”. Rowan Cheung, a népszerű Rundown AI hírlevél szerzője, aki az utóbbi időben Mark Zuckerberggel, a Meta vezérigazgatójával és Demis Hassabissal, a Google DeepMind vezetőjével készített interjút az AI-fejlesztéseikről, az X-en olyan áttörésnek nevezte az o3-at, ami szerinte jelentősen leköröz a teszteken minden korábbi modellt. Mark Knoop, az ARC Prize társalapítója az o3-at „rendkívül különlegesnek” ítélte az X-en, és Kamradthoz hasonlóan úgy vélekedett, hogy mindenkinek újra át kell gondolnia, hogy mire képes vagy nem képes az AI. „Bár ez még csak a kezdet, ez a modell valós intelligencianövekedést mutat” – írta.
Január végén érkezik az o3 mini
De mikor kezdhetjük el használni az új chatbot modellt? A cég AI-biztonsággal foglalkozó kutatóknak már pénteken, meghívásos alapon elérhetővé tette az o3 mini-t, amit Hongyu Ren a bemutatón erőforráshatékony, „gondolkodó” modellnek nevezett. Az o3 mini, ami az OpenAI szerint az o1 modelleknél sokkal gyorsabban reagál majd kérdéseinkre, három különböző módban képes működni, kevés, közepes és sok érvelési képességgel.
Altman az o3 mini-ről azt mondta, hogy „az árhoz viszonyított teljesítmény tekintetében lenyűgöző mértékű növekedést látunk ahhoz képest, amit az o1-el tudtunk nyújtani”. A bemutató legviccesebb (vagy legijesztőbb) pillanata csak ezután következett. Chen felvetette, hogy amikor jövőre újra beszélgetnek, megkérik majd az o3 minit bemutató Ren-t, hogy utasítsa arra a modellt, hogy az kezdje el önmagát fejleszteni. „Persze, kérjük meg következőleg a modellt, hogy fejlessze magát”, reagált Ren, de Altman közbeszólt és rögtön lehűtötte a kedélyeket. „Talán inkább ne” – mondta.
Altman novemberben kisebb meghökkenést váltott ki, amikor arról beszélt, hogy izgatottan várja 2025-re a mesterséges általános intelligencia eljövetelét. Annak alapján, amit az o3-ról jelenleg tudunk, ez a kijelentés már nem csupán egy, a befektetők felcsigázására bedobott marketingfogásnak tűnik. Az pedig, hogy az o3-nak és utódainak milyen társadalmi, gazdasági, politikai hatásai lesznek, a következő hónapokban és években derül majd ki.
Kapcsolódó cikkek a Qubiten:

Videógenerátor, ChatGPT Pro, beszélgetés a Mikulással – félidőnél jár az OpenAI 12 napos karácsonyi akciója
Az OpenAI karácsonyig 12 újdonságot jelent be, és az már az eddigiek alapján is látszik, hogy egyre nagyobb hangsúlyt fektet a ChatGPT hangos és videós funkcióira. Megjelent a szövegből rövid filmeket gyártó Sora is, de milyen nagy dobást tartogatnak még?

Sam Altman szerint 2025-ben már eljöhet a mesterséges általános intelligencia
A szinte minden emberi feladat elvégzésére képes AGI pillanata az OpenAI vezére szerint olyan gyorsan el is illan majd, amilyen gyorsan eljön.

Húsz terület, ahol a ChatGPT már most megkönnyíti az életedet
Ha a Google a barátunk, akkor minek nevezzük az AI-chatbotokat, amik egyszerű válaszok helyett már részletes magyarázatokat adnak, és még vissza is kérdezhetünk? Tippek és trükkök a főzéstől a nyelvtanuláson át a lelki segélyig.

Óriásit fejlődött az új ChatGPT: készítői szerint már gondolkodik, érvel és komplex feladatokat old meg
Az OpenAI o1 nevű új modell fizikából, kémiából és biológiából már egy PhD-hallgató szintjén teljesít, de a matekolimpián is 83 százalékot érne el az eddigi legfejlettebb modell 13 százalékához képest.
Kapcsolódó cikkek