Az egész emberiség kárára válhat, ha továbbra is csak a nagy techcégek fejlesztik a mesterséges intelligenciát

Amióta az OpenAI amerikai kutatócég tavaly novemberben közzétette a ChatGPT-t, a szoftver óriási hullámokat kavart. Legutóbb az orvosi szakvizsgát tette le 60 százalék körüli eredménnyel, megjelent komoly tanulmányok társszerzőjeként, és valószínűleg évek óta ez az első olyan fejlesztés, ami komolyan megszorongathatja a Google egyeduralmát a keresőmotorok piacán. A teljes képhez azonban az is hozzátartozik, hogy az OpenAI kétszáz moderátort alkalmazott két dolláros órabérért Kenyában arra, hogy kigyomlálják a ChatGPT-ből a toxikus tartalmakat. A világszenzációt keltő chatbot ugyanakkor csak a jéghegy csúcsa: a tanuló algoritmusok szépen csendben forradalmasítják szinte az összes ipari és kereskedelmi szektort, a nagy átalakulás haszna és kára azonban távolról sem oszlik meg egyenlően.
Egy amerikai piacelemző cég 2021-ben 93,5 milliárd dollárra becsülte a globális AI-piacot, ami jelenleg már körülbelül 136,6 milliárd dollárt érhet, és 2030-ig 38,1 százalékos éves növekedést produkálhat. Ez a PwC felmérése szerint azt jelenti, hogy hét év múlva a mesterséges intelligencia 15,7 trillió dollárral járulhat hozzá a globális gazdasághoz.
Óriási különbségek vannak azonban abban, milyen cégek és milyen országok tudnak profitálni mindebből, és kik azok, akiknek csak a felhasználói szerep jut. A Mozilla Internet Health Report 2022 a tavalyi évre vonatkozóan is igyekezett feltárni a mesterséges intelligencia fejlesztésére vonatkozó aszimmetriákat; a szerzők szerint ez azért fontos, mert az egész internet egészsége szempontjából is az AI körüli egyensúlytalanságok jelentik a legnagyobb kihívást.
Erősíteni kellene a nagy techcégektől független AI-fejlesztést
A minden évben kiadott jelentést a teljesen ingyenes és nyílt forráskódú Firefox böngészőt is jegyző Mozilla Alapítvány adja ki, amelyik azért küzd, hogy az internet továbbra is mindenki számára elérhető és nyitott, közösségi erőforrás maradjon, hogy felelősségre vonhatók legyenek a nagy techcégek, mint a Google, a Facebook vagy a Microsoft, és az egyes felhasználók ne degradálódjanak a figyeleméhes felületek kattintgató rabszolgáivá.
A 2022-es Mozilla Internet Health Report ötrészes podcast formájában is elérhető, amelyben a megfigyelés és a háború, a kiszállítás és a közösségi autózás kiegyenlítetlen erőviszonyait, a térképekben mutatkozó adathiányokat, a választási dezinformációs kampányokat és a tanuló algoritmusokhoz használt egészségügyi adatkészletek előítéletességét járják körbe az ecuadori Quito kiszállítóitól a dél-afrikai Tembisa városka piacaiig, ahol egy AI-kutató az apartheid térbeli örökségét tárja fel műholdképek segítségével.
Solana Larsen, a tanulmány egyik szerkesztője szerint a mesterséges intelligencia feletti befolyás és ellenőrzés központosodása a legtöbb ember számára valójában egyáltalán nem pozitív fejlemény. Arra van szükség, hogy erősítsük a nagy techcégek és kockázati tőkealapok által finanszírozott startupok birodalmán túli technológiai ökoszisztémákat, hogy teljes egészében a megbízható AI-rendszerek bontakoztathassák ki a bennük rejlő potenciált – mondta Larsen.
Az Egyesült Államok többet fektet AI-fejlesztésbe, mint mindenki más együttvéve
Azok a techcégek és azok az országok, amelyek megfelelő mennyiségű adathoz, tehetséges fejlesztőkhöz és technológiai infrastruktúrához férnek hozzá, elképesztő versenyelőnyökhöz jutnak, és már most is elkezdték a szoftverek és hardverek feletti dominanciájuk olyan mértékű konszolidációját, amely alapvetően határozza meg, hogyan használják világszerte a mesterséges intelligenciát.
A Mozilla beszámolója szerint az Egyesült Államokban több mint 50 milliárd dollárt fektettek magánkézben lévő cégek tanuló algoritmusok fejlesztésébe, ez pedig nagyhából háromszor annyi, mint Kínában. Ehhez persze érdemes megnézni azt is, hogy Kínában az állam mennyire dotálja a mesterséges intelligenciával kapcsolatos kutatás-fejlesztést, azt látjuk azonban, hogy a korábbi beszámolókkal ellentétben a kínai befektetés korántsem akkora, mint amire számítanánk, bár a Kínából érkező információk körül általában van bizonytalanság. Az állami költés nem katonai AI-célokra egyes becslések szerint 2-8,4 milliárd dollár között mozoghatott 2018-ban, ami a magánbefektetésekhez hozzátéve is messze elmarad az USA mögött. Az amerikai kormány egyébként 2022-ben még plusz 1,67 milliárd dollárt költött nem katonai AI-célokra.
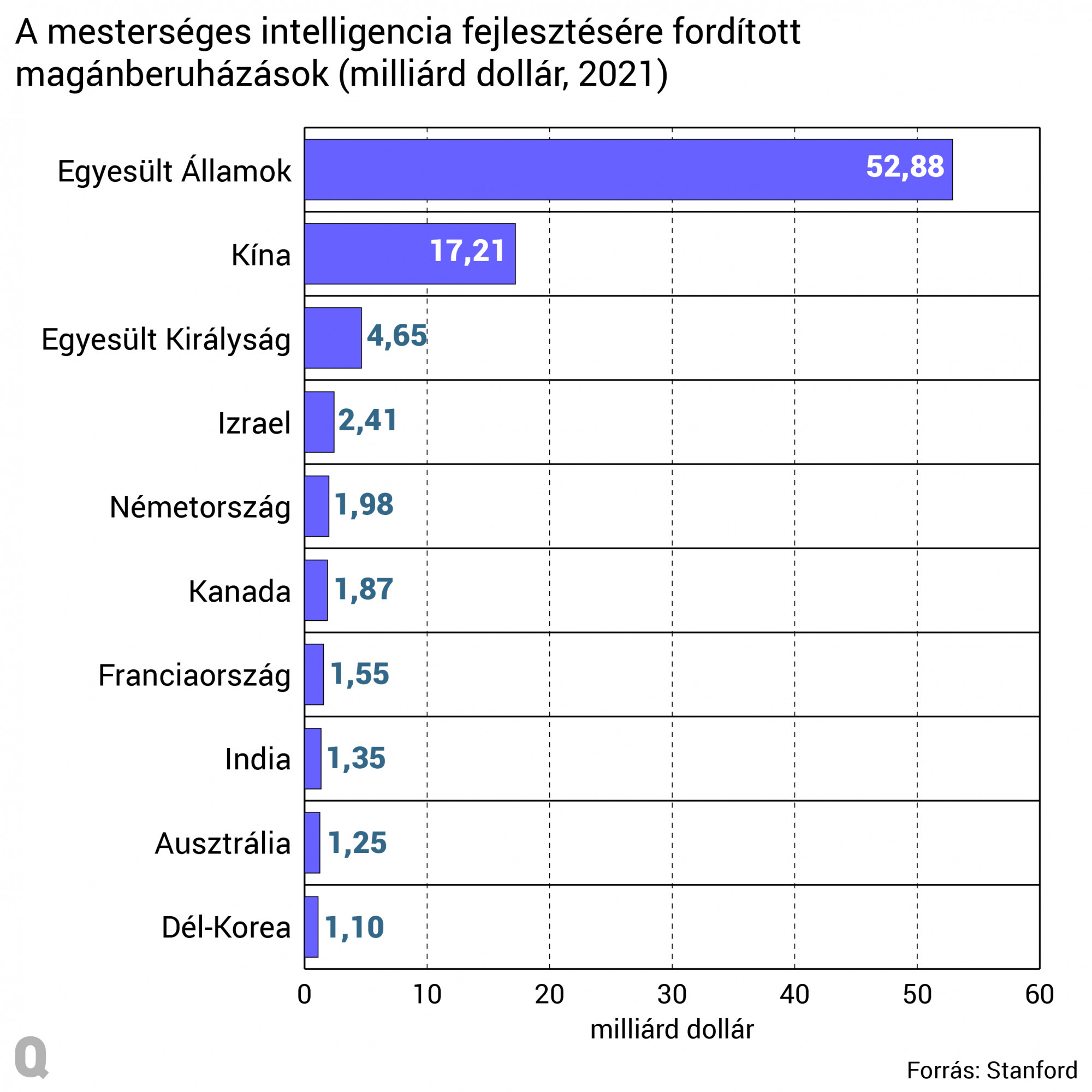
Főleg amerikai mércéhez mérik az algoritmusok teljesítményét
A befektetések mértéke azonban csak egy indikátora annak, hogyan koncentrálódnak a mesterséges intelligencia körüli erőviszonyok. A Mozilla beszámolója szerint az utóbbi években egyre csökken a gépi tanuló szoftverek betanításának költsége, és egyre több adat érhető el a tanításukhoz, így a világ egyre több pontján foglalkoznak mesterséges intelligencia elérésére törekvő algoritmusok fejlesztésével.
Az algoritmusfejlesztéseket részletező tanulmányok világában azonban további súlyos egyenlőtlenségek rejlenek. A Kaliforniai Egyetem (Los Angeles) szociológiai tanszékének egy kutatócsoportja 2021 végén arra jutott, miután 2015 és 2020 között 26 535 AI-kutatással foglalkozó tanulmányt vizsgált meg, hogy az algoritmusok teljesítményének összehasonlításához referenciaként mintegy 1933 adatkészletet összesen 43 140 alkalommal használtak a kutatók és fejlesztők, és ezek a referencia-adatkészletek nagyon kevés helyen koncentrálódnak.

Ez nem csupán amiatt érdekes, mert kiderül belőle, hogy ezen adatok szerint az Orbán Viktor miniszterelnök által a világ ötödik leginkább high-tech országának tartott Magyarország egyetlen alkalommal sem használt hasonló algoritmus-értékelő referenciaadathalmazt, hanem amiatt is, mivel az látszik belőle, hogy csupán néhány intézmény és cég formálja azt, hogyan gondolkodjunk az AI-fejlesztésről és ki profitáljon belőle, ráadásul azok felé billen a mérleg nyelve, akik már eleve erőteljesen formálják a felhasználók internetes viselkedését.
Sőt ezeknek a referencia-adathalmazoknak, amelyek több mint 26 ezer AI-tanulmányban jelennek meg, több mint felét 12 elitintézmény és technológiai cég jegyzi, túlnyomó többségük pedig az Egyesült Államokban található.
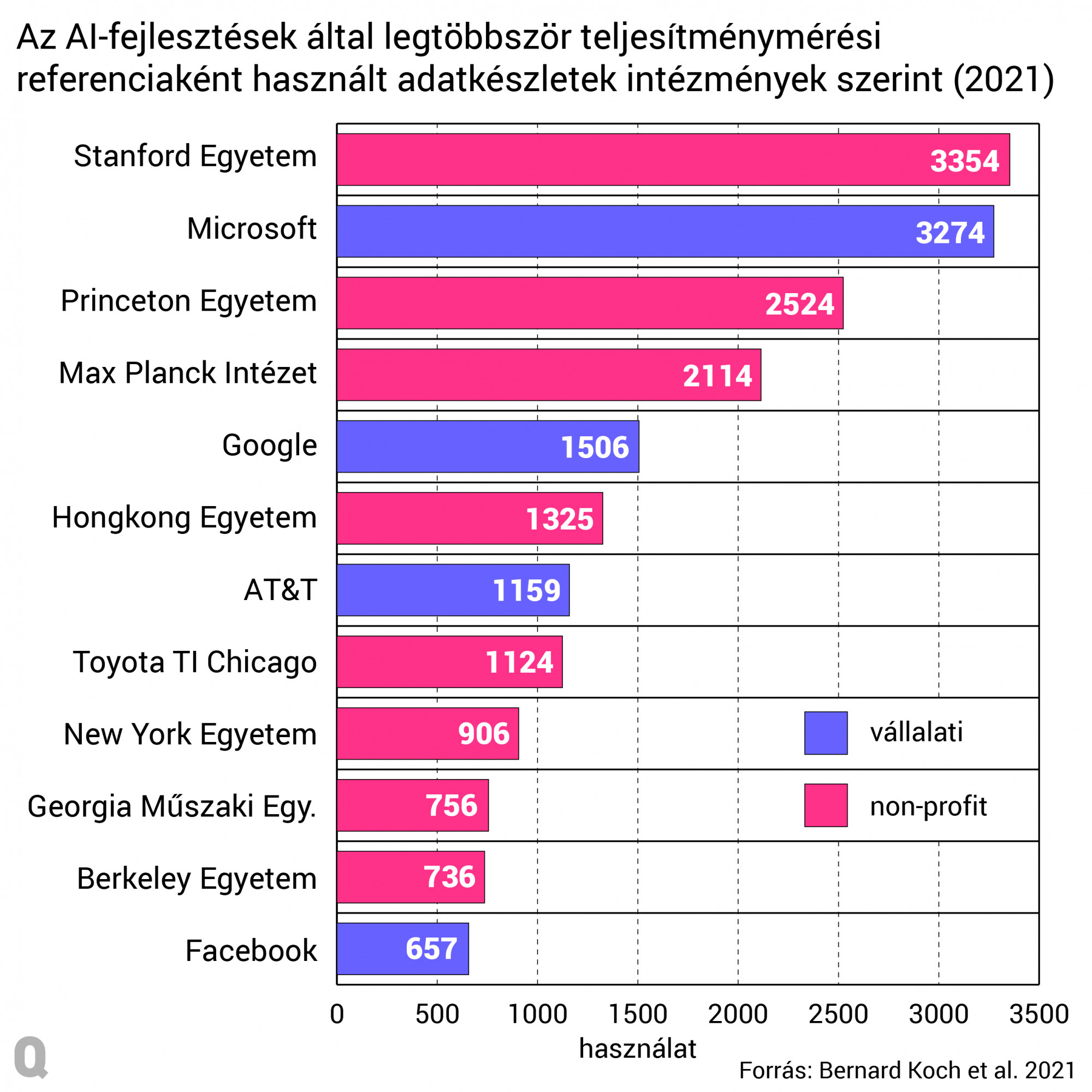
Ráadásul ezeknek a hatalmas és gyakran használt adathalmazok adataiban, amelyeket általában az internetről szednek össze, túlsúlyban lehetnek az amerikai, fehér és férfi minták – mint ahogy az több, erősen előítéletes algoritmus esetén kiderült. Például volt olyan szoftver, amelyik 2019-ben rosszabb egészségügyi ellátásban részesítette volna a színes bőrűeket, a Facebook ajánlórendszere pedig 2021-ben főemlősként kategorizált egy fekete férfiakról szóló videófelvételt.
Nem szabad a Big Tech kezében hagyni az AI-kutatást
Szintén aggodalomra ad okot, hogy az elmúlt években egyre több mesterségesintelligencia-kutatást finanszíroznak a nagy techcégek - vagy közvetlenül vagy elit egyetemi kutatócsoportokon keresztül. A Mozilla Alapítvány kutatása szerint arra lenne szükség, hogy többféle intézmény és kutatócsoport vehessen részt a mesterséges intelligencia kialakításában és formálásában, hogy az iparág normáit a tisztán profitalapú megközelítésből, amely nem feltétlenül szolgálja az AI-alapú algoritmusok felhasználóinak az érdekeit, el lehessen mozdítani közérdekűbb irányba.
Kapcsolódó cikkek a Qubiten:

A ChatGPT külön felkészítés nélkül is letette az orvosi szakvizsgát
Az amerikai orvosi szakvizsgára jó esetben is hónapokig készülnek a hallgatók, de az OpenAI mesterséges intelligenciája percek alatt megcsinálta, 60 százalék körüli eredménnyel.

Ez egyszer az emberiség történetében szeretnénk nem utólag bénázni, amikor feltakarítunk a technológia után
Kell-e foglalkoznia a száguldó villamos problémájával egy önvezető autót fejlesztő informatikusnak? Vajon felállítanak-e a jövőben algoritmus-felügyeletet? Mi a közös az intelligens kutyákban és a robotokban? Mit kezd majd a bíróság a kvázi-személyekkel? Héder Mihállyal, a BME filozófia és tudománytörténet tanszékének docensével beszélgettünk.

Kína elhatározta, hogy AI-nagyhatalom lesz, és két év alatt le is hagyta az USA-t
2017-ben hirdették ki a mesterségesintelligencia-fejlesztési tervet, mára pedig a világ AI-cégeinek felét Kína finanszírozza. Az ország időközben kitermelte a saját Google-Facebook-Amazon trióját.
Kapcsolódó cikkek


