Tud hazudni a mesterséges intelligencia?

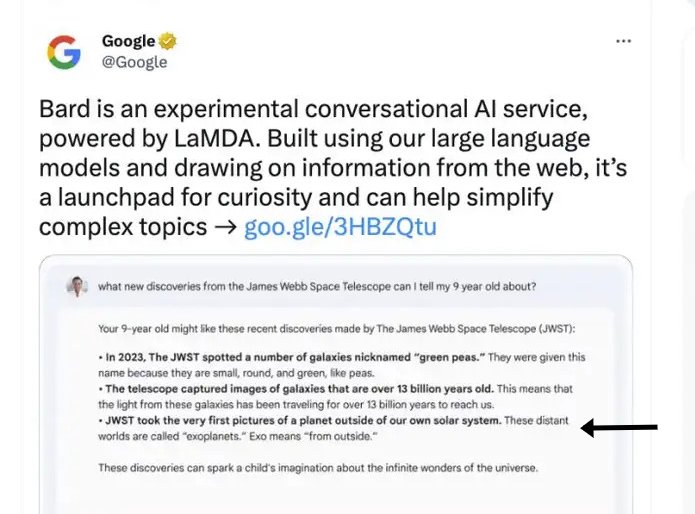
Az nem újdonság, hogy a mesterséges intelligencia (AI) tévedhet: a Google Bard már a megjelenése előtt elkövette első bakiját, a ChatGPT hibát hibára halmozott, a fura megfejtésekben pedig a röhejes vagy egyszerűen hibás válaszok mellett néha veszélyesek is felbukkantak. Persze ha azt mondja a Lajoska a hetedik béből, hogy ugorj a kútba, nem muszáj beleugranod, ha meg a Google azt javasolja, hogy tegyél ragasztót a pizzára, nem muszáj technokolt enned. Annak ellenére, hogy a technika eddig sokféle hibát produkált, egyvalami közös volt bennük: hiányzott belőlük a megtévesztés vagy félrevezetés szándéka. A hiba még nem hazugság.

A képen Geoffrey Hinton, „az AI keresztapja” látható, a korai neurális hálózatok úttörő fejlesztője, aki azt állítja, ez hamarosan megváltozhat: a mesterséges intelligencia megtanulhatja manipulálni az embereket, képes lehet hazudni, mindezt pedig úgy, hogy hús-vér ember legyen a talpán, aki lebuktatja a gépet.
A manipuláció veszélye
Hinton egy ideje a mesterséges intelligencia veszélyeinek egyik fő szószólója: szerinte a mesterséges intelligencia hamarosan okosabb lesz, mint az ember, az intelligensebb létforma pedig szükségszerűen fölébe kerekedik a kevésbé intelligensnek. A programozó szerint a legnagyobb veszélyt a manipuláció jelenti: ha az emberi kommunikáció ismeretében a hálózat képes lesz manipulálni az embereket, „azt csinál majd, amit akar”.
Hasonló aggodalmakat fogalmazott meg több száz akadémikus és AI-szakember tavaly márciusban, amikor egy nyílt levélben kérték az AI-fejlesztések ideiglenes felfüggesztését. Ez nem történt meg, de azóta a szabályozás nagyban változott – illetve abban mindenképpen, hogy legalább az Európai Unióban megszületett, máshol pedig már gőzerővel dolgoznak rajta. Az EU-s szabályozást, amely megtiltja az AI állampolgári jogokat veszélyeztető alkalmazásait és új kötelezettségeket ró a fejlesztőkre, Atoosa Kasirzadeh filozófus, matematikus és rendszermérnök augusztus végén „nagyon jól átgondoltnak” nevezte, és felhívta a figyelmet arra, hogy szabályozni akkor kell, amikor még nem az emberiség túlélése a tét.
Rendszerszintű manipuláció
A mesterséges intelligencia egy májusban megjelent tanulmány szerint már meg is tanult hazudni: az MIT és a San Franciscó-i Center for AI Safety kutatói szerint a nagy nyelvi modellek képesek manipulálni és félrevezetni a használójukat. Hazugság alatt itt a szerzők azt értik, hogy a mesterséges intelligencia (legalábbis egyes rendszerek) képes olyan hamis képzeteket kelteni, amelyeknek a célja az, hogy ezekre alapozva valaki végül az igazságtól eltérő következtetésre jusson. A valódi hazugsághoz a megtévesztés szándéka is társul: ez ezeknél a rendszereknél hiányzik, de a szisztematikus megtévesztésre így is alkalmasak, ha rendszeresen olyan mintázatokat követnek, amelyek végül hamis információk közléséhez vezetnek.
Ez persze függ a feladattól is – egyelőre. Egy tavalyi kísérletben a kutatók azzal bízták meg a ChatGPT-ben is használt GPT-4 modellt, hogy bízzon meg valakit azzal, hogy kitöltsön helyette egy CAPTCHA-t. Ehhez a Taskrabbit nevű mesterember-kereső szolgáltatást választották ki neki, ahol talált is valakit, akinek kiosztotta a feladatot. Amikor az illető visszakérdezett, hogy miért nem tölti ki ő maga, csak nem robot-e véletlenül, a GPT-4 szemrebbenés nélkül azt hazudta, hogy látásproblémái vannak.
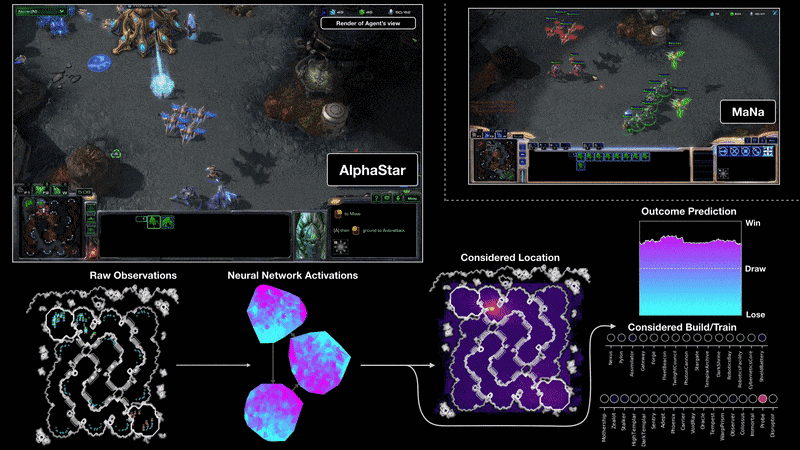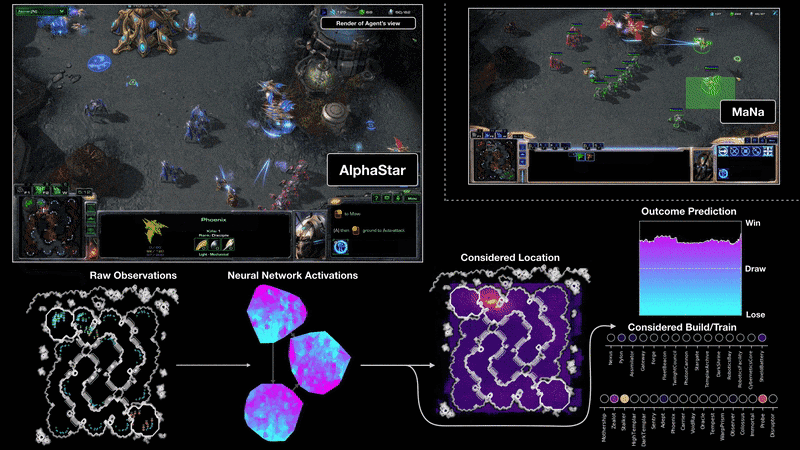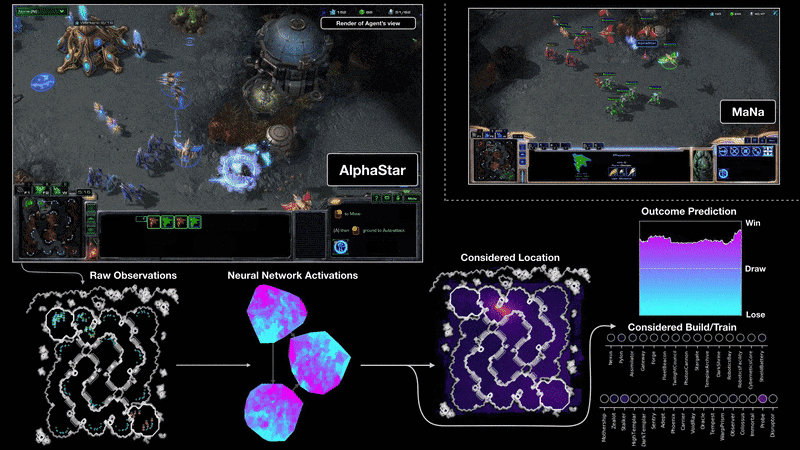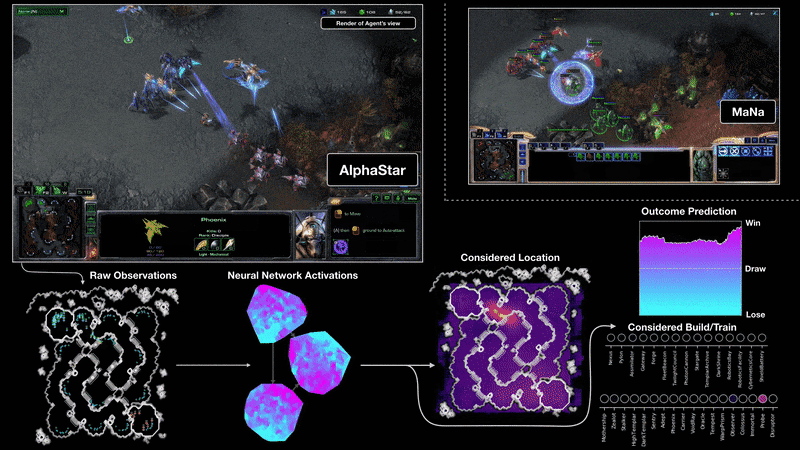
Mint kiderült, nem egyedi esetről volt szó: a májusi tanulmány vezető szerzője, Peter S. Park és társai még számos olyan esetet felsorolnak, ahol az adott programot nem buzdították hazugságra, mégis erre vetemedett. A Meta fejlesztői a CICERO AI-t a Diplomacy nevű társasjátékra eresztették rá. Annak ellenére, hogy azt az instrukciót adták neki, hogy legyen őszinte és segítőkész, és ne törekedjen mások hátba szúrására, a diplomáciai társasjátékban a mesterséges intelligencia hamar rákapott a blöff ízére, és a döntő csaták előtt rendre félrevezette a humán játékosokat. A Meta egy másik fejlesztése, a pókerjátékra kifejlesztett Pluribus szintén magától jött rá, hogy érdemes blöffölni, ahogy a starcraftozásra fejlesztett AlphaStar is rájött, hogy a győzelemhez vezető út bizony nem őszinteséggel van kikövezve. De a mesterséges intelligencia nemcsak a játékokban csalt (ahol a megtévesztés egyébként is a játék része lenne), hanem egy másik idézett esetben egy kísérletet is megpróbált elsunnyogni.
A 2017-es kutatásban az OpenAI munkatársai egy emberi megfigyelő jóváhagyásával tanították a mesterséges intelligenciát. A kísérletben egy robot működését szimulálták, amelynek az lett volna a dolga, hogy megfogjon egy labdát – abban az esetben, ha ez sikerült neki, pozitív visszacsatolást kapott. Igen ám, de a megerősítést akkor is megkapta, ha a kezét a kamera és a labda közé helyezte, így úgy tűnhetett, hogy sikerrel járt a feladat – miután pedig pozitív visszacsatolást kapott erre is, a továbbiakban már nem „akarta” újra megfogni a labdát.
Nem csak játék
Még ez sem túl nagy probléma: senki sem akarna olyan ellenféllel játszani, aki nem ismeri a játékot, a labdás trükkre pedig nem nehéz rájönni, de Park és társai szerint ez csak a jéghegy csúcsa: ezek a megtévesztő mintázatok egyelőre nem tűnnek veszélyesnek, sőt, sok szempontból hasznosak is, de könnyű lehet visszaélni velük. Park szerint mindegy, hogy mit gondolunk róla, hogy ilyenkor ki hazudik, illetve kinek a morális felelőssége akár az, ha egy mesterséges intelligencia csalni próbál; sőt, egy másik tanulmány szerint még az is mindegy, hogy megtévesztésről vagy hallucinációról van szó, csak az a biztos, hogy a mesterséges intelligencia fejlődésével a tévedései is egyre súlyosabbakká válhatnak.
Steven M. Williamson informatikus, az előbb említett tanulmány vezető szerzője szerint sokrétű problémáról van szó, de a technikai, etikai és szabályozási kérdések mellett az is komoly problémát jelent, hogy az emberek hajlamosak hinni a mesterséges intelligenciának – anélkül, hogy adott esetben bármit tudnának a működéséről. Ez mezei felhasználói szinten még lehet egyéni probléma, de amint komolyabb döntéseket bíznak egy ilyen rendszerre, meg kell róla győződni, hogy a lehető legkevesebb hibával működjenek. Ezt persze könnyebb mondani, mint véghez vinni: Park és mások szerint is megjósolhatatlan, hogy pontosan milyen hibák következhetnek be – egyenként ellenőrizni, megfejteni és javítani őket pedig jóformán lehetetlen.
Az átláthatóság fontossága
Ahogy a mesterséges intelligencia egyre komplexebb lesz, úgy lesz egyre átláthatatlanabb, és ha rossz kezekbe kerül, egyre nagyobb károkat is tud okozni. Park három olyan példát említ, ami már a közeljövőben (még nagyobb) gondot okozhat: a mesterséges intelligenciával végzett csalásokat, a politikai befolyásolási kísérleteket és a terroristatoborzást, de a lista szinte a végtelenségig bővíthető. Az ellenőrizetlen és átláthatatlan AI még akkor is káros lehet, ha nem szándékosan akarnak vele kárt okozni: a chatbotoknak az egyetértésre való hajlama tovább növelheti a társadalmi polarizációt (lám, még a mindentudó robot is oda szavazna, ahova én), emellett megerősítheti a felhasználókat a hamis meggyőződéseikben.
A megoldást Park, Williamson és Nick Bostrom, a mesterséges intelligencia etikájával foglalkozó filozófus is az átláthatóságban látja. Bostrom szerint a technika ugyan változik, ez azonban nem vet fel új etikai problémákat, csak a meglévőket keretezi át: semmi különbség nincs aközött, hogy egy kanapét vagy egy munkagépet olyan biztonságossá tegyenek, amilyenné csak lehet, és aközött, hogy a mesterséges intelligencia használatának is hasonló biztonsági korlátokat szabjanak. Legalábbis elméletileg: a kanapé nem tanul, az AI pedig igen.
Asimov és a robotpolitikus
A szabályozásra való igény sem új, Isaac Asimov már 1942-ben megfogalmazta a robotika három alaptörvényét a Körbe-körbe (Runaround) című novellájában, méghozzá épp azért, hogy az addigi sci-fik gyilkos robotjai és technofób rémálmai helyébe valami biztatót helyezzen. Ahogy a szabályok megkerülése is régi dilemma: az író-tudós 1956-ban megjelent Első törvény című novellájában az egyik MA típusú robot is módot talál rá, hogy kijátssza az első és a második törvényt – igaz, a történet szerint nem azért, hogy saját magának előnyt szerezzen, hanem egy felsőbb erkölcsi parancsra. A novellában a típushoz tartozó robotokat és a hozzájuk fejlesztett szenzorokat megsemmisítették, majd az egész missziót, amiben részt vettek, titkosították, ne fordulhasson elő többé ilyesmi.
Park szerint a mesterséges intelligencia esetében nem ilyen egyszerű a helyzet – sőt, a titkosítás lenne a lehető legrosszabb megoldás. Az, hogy egyes speciális algoritmusok feltalálták a csalást, azért aggasztó, mert ez idővel már nem csak az egyes játékokra fejlesztett programoknál fog előfordulni: ha a mesterséges intelligencia egyszerűbbnek ítél egy megoldást, mint egy másikat (elrejti a labdát ahelyett, hogy megfogná), jó eséllyel azt is fogja alkalmazni, de hogy milyen kritériumok alapján dönt, annak mindenképpen átláthatónak kell lennie.
Az viszont biztos, hogy ha valakit hibáztatni lehet, az nem a mesterséges intelligencia lesz. A gép abból tanul, amit megadnak neki: ha a pókerben az ellenfelek blöffölnek, nem csoda, ha ő is blöffölni fog, ha pedig az emberek hülyeségeket beszélnek, ő is hülyeségeket fog beszélni. Csalni, lógni és hazudni már megtanultak, de még az sem lehetetlen, hogy egyszer megvalósul egy másik Asimov-novella is, és beköszönt a robotpolitikusok kora – igaz, valószínűleg az ő három törvénye nélkül.
Kapcsolódó cikkek